


1、三级模式结构和两级映射
1.1 三级模式结构
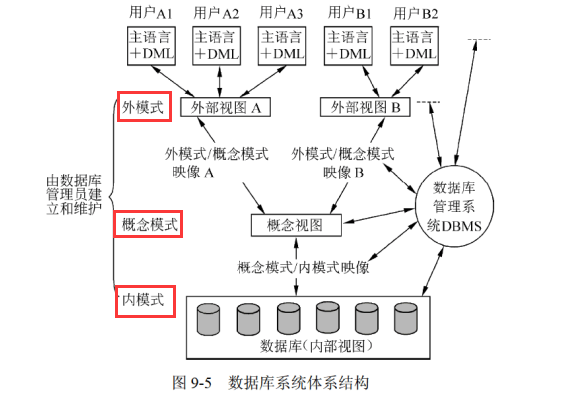
-
外模式(用户模式或子模式)------视图
-
概念模式(模式)----基本表
-
内模式(存储模式)------存储文件
1.2 两级映射


2、数据模型
2.1 概念数据模型


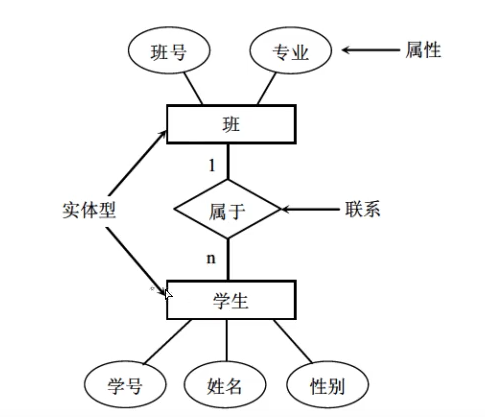
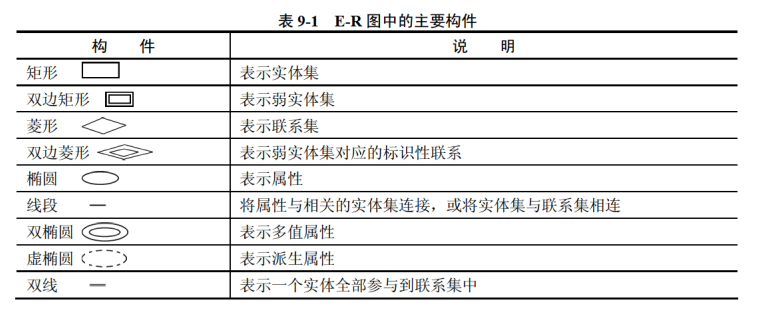
2.2 结构数据模型


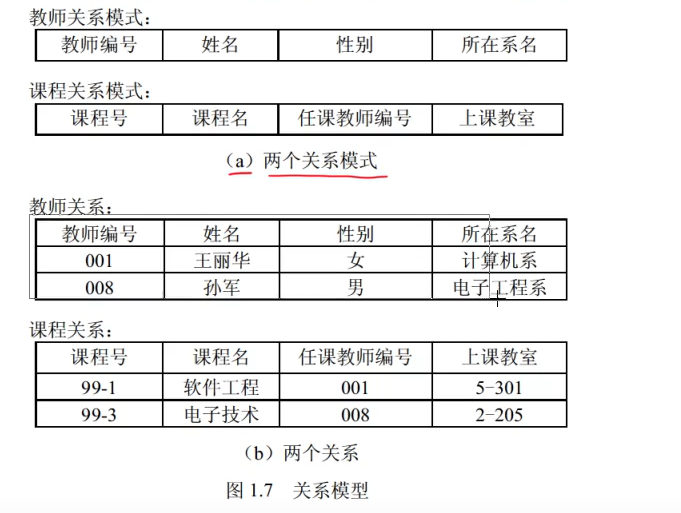

3、关系代数
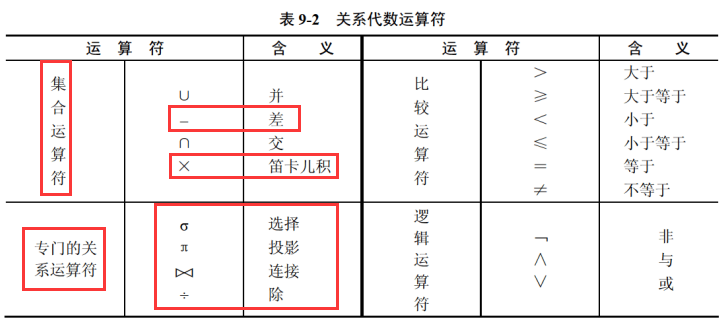
3.1 集合运算符

3.2 投影和选择


注意带冒号和不带冒号的差别
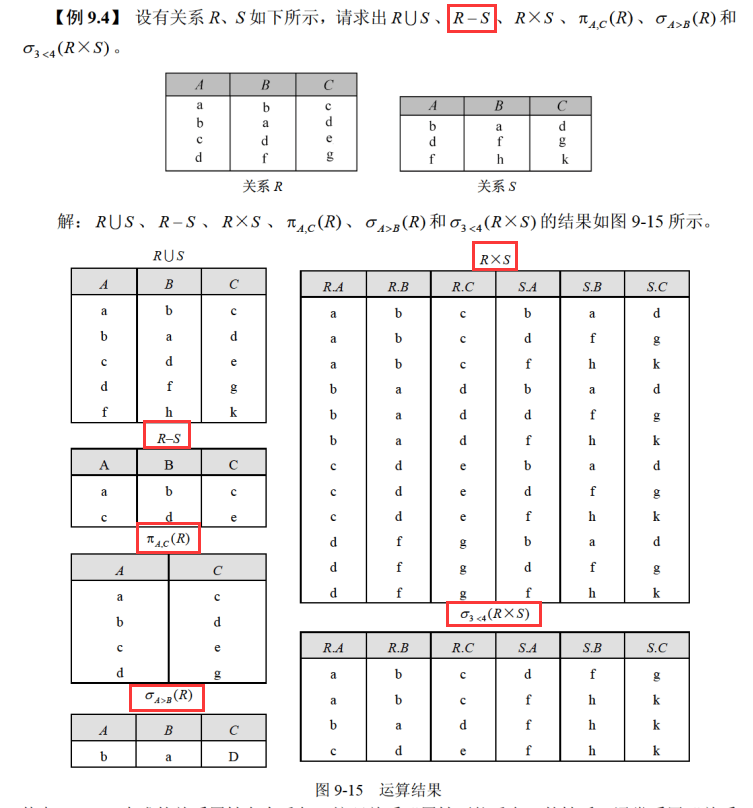
3.3 连接运算符
θ连接

连接其实就是在两个关系的笛卡尔积中选择符合条件的行,而上面这种连接其实就是用比较运算符来进行比较
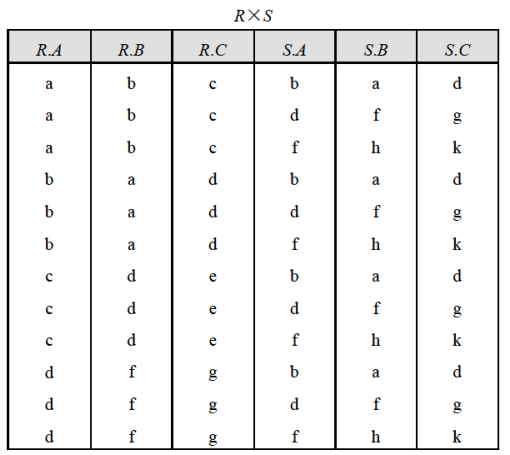
等值连接

等值连接就是笛卡尔积中某一列和另外一列相等就符合要求,然后选择出来就行了
自然连接

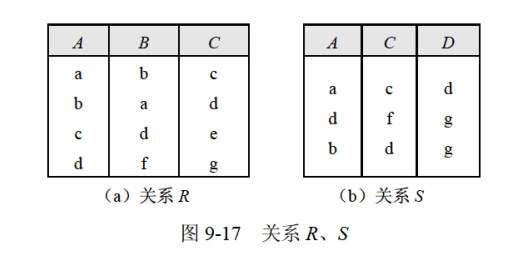
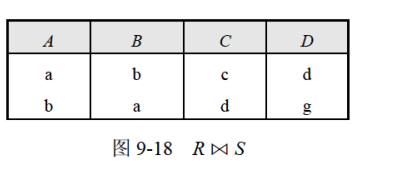
在笛卡尔积中找R.A=S.A并且R.C=S.C
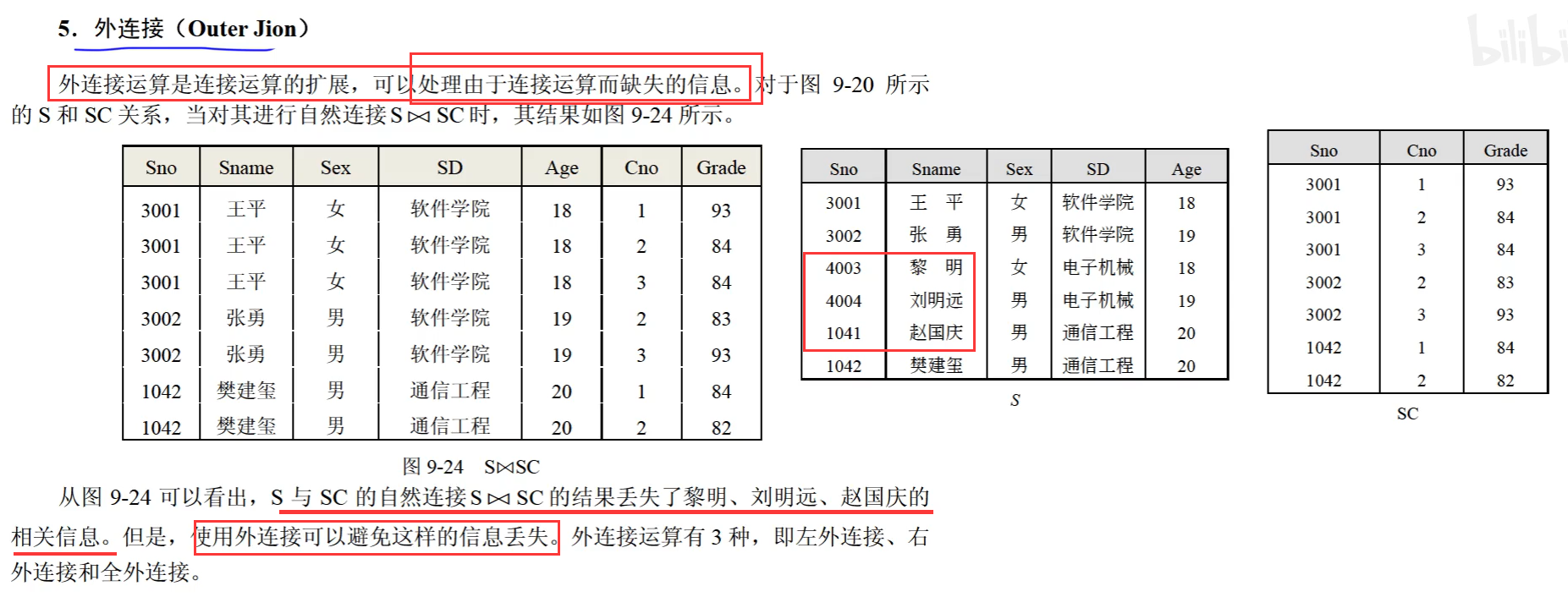
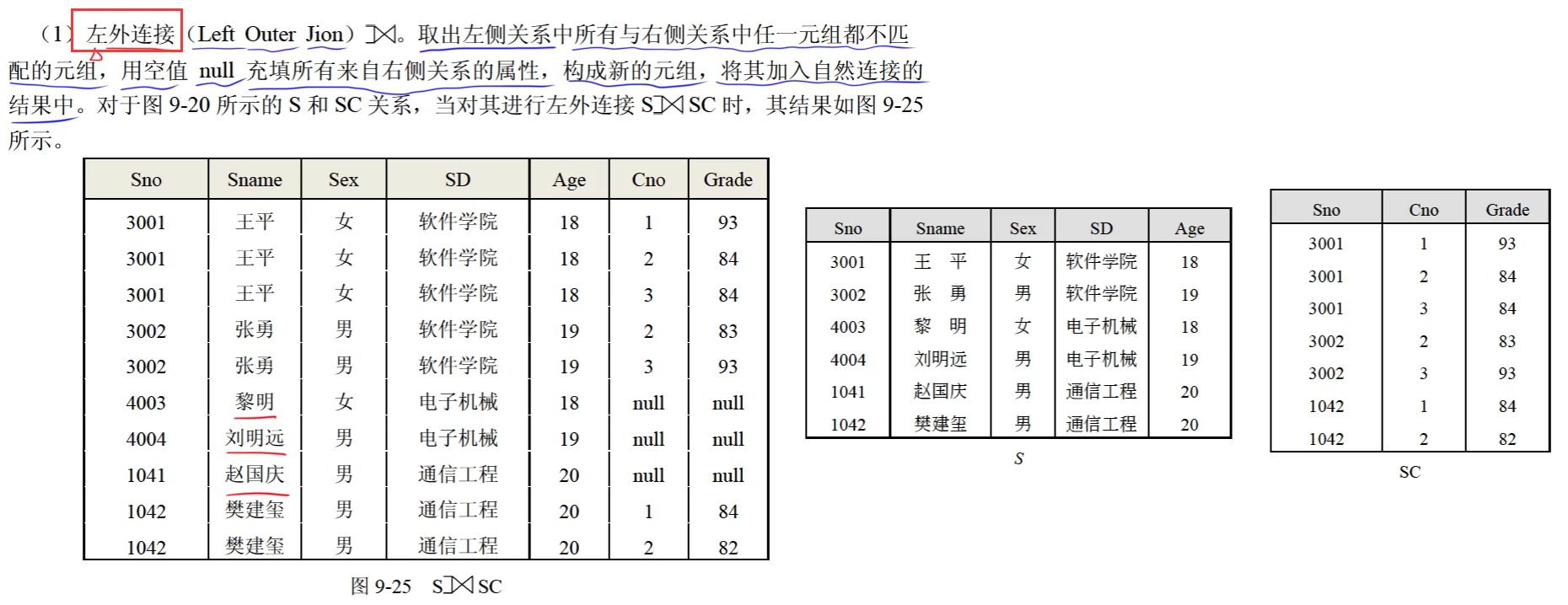
左外连接
右外连接
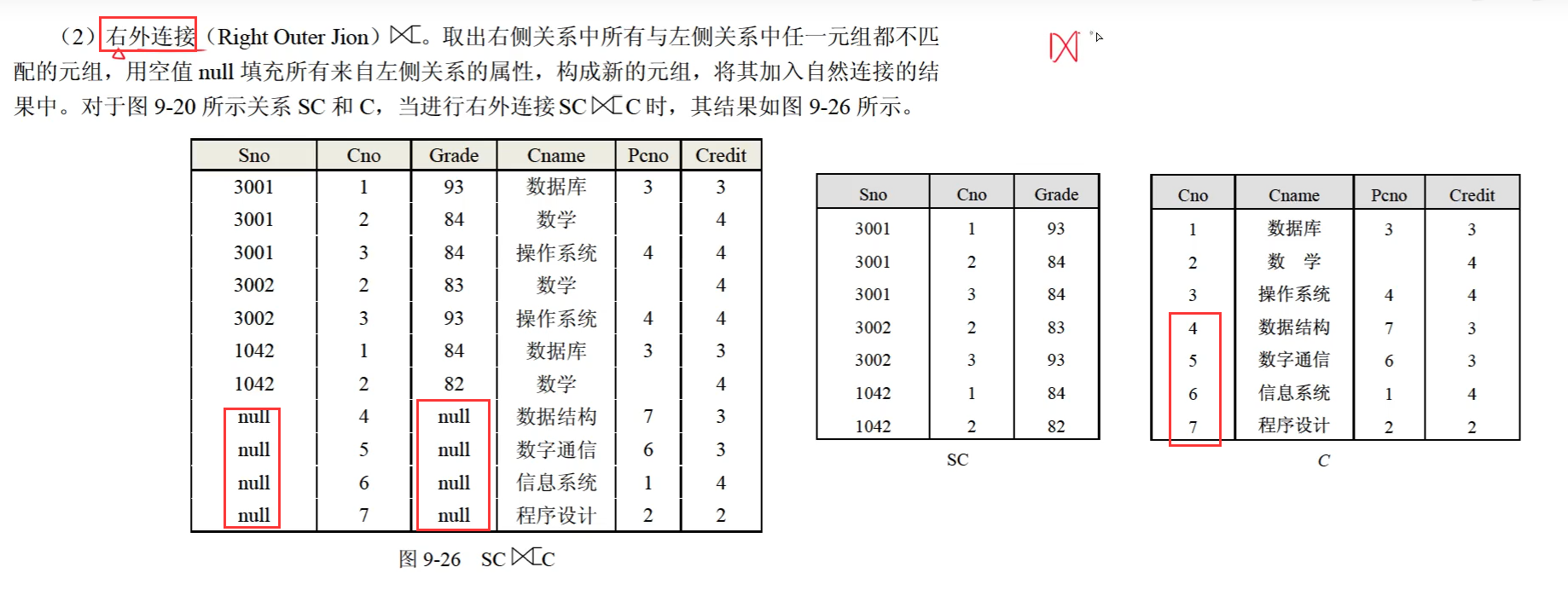
全外连接
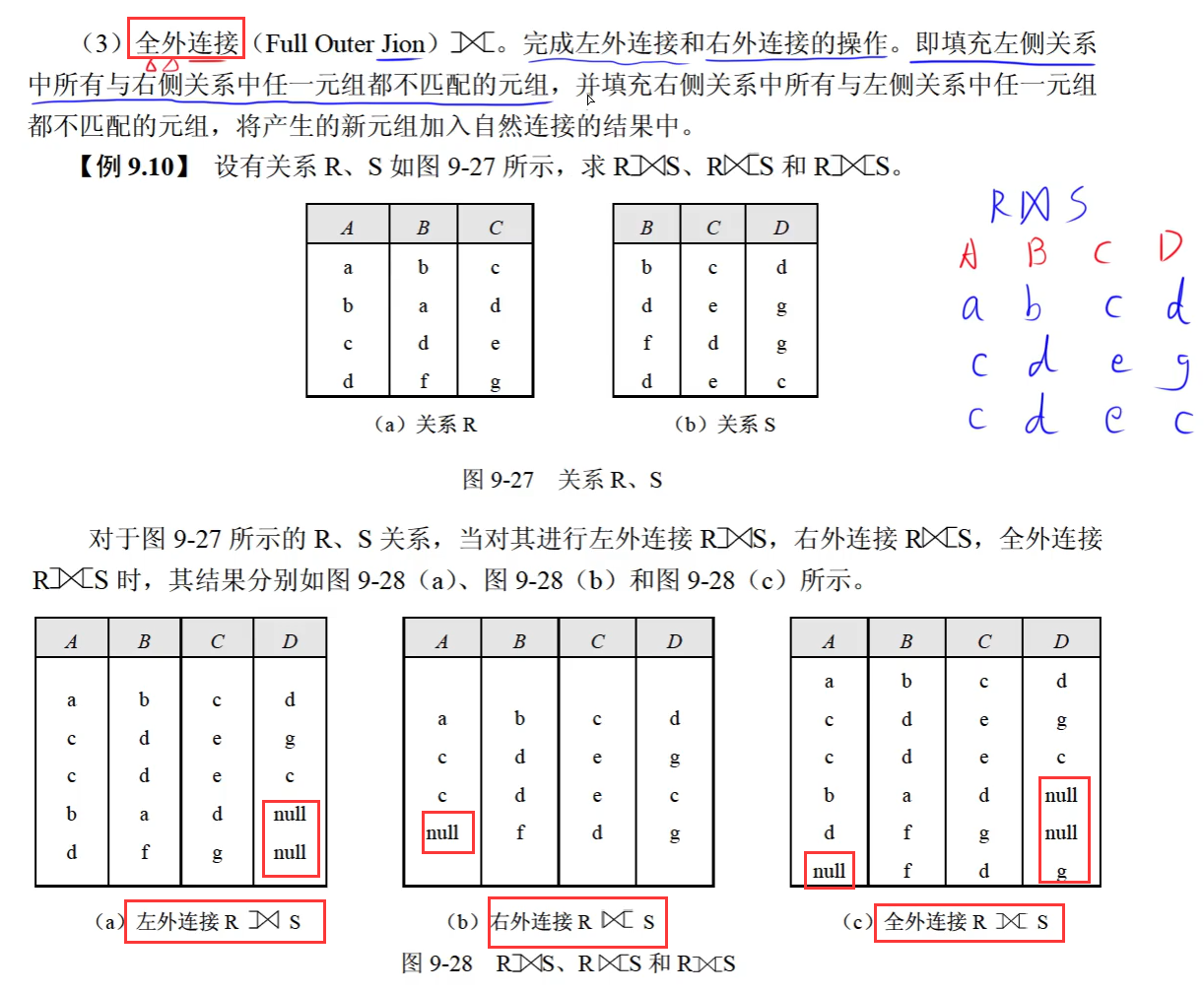
全外连接是自然连接的结果加左右外连接的结果
3.4 逻辑运算符
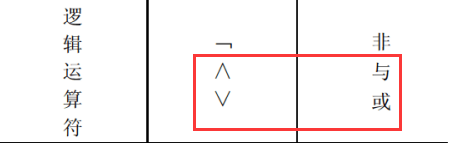
这里与和或是用来连接上面选择或者投影的条件的连接词,与就是and,或就是or,或只要两边条件有一方满足就可以了
真题
答案:(55)B (56) A


答案:(54)C (55)B

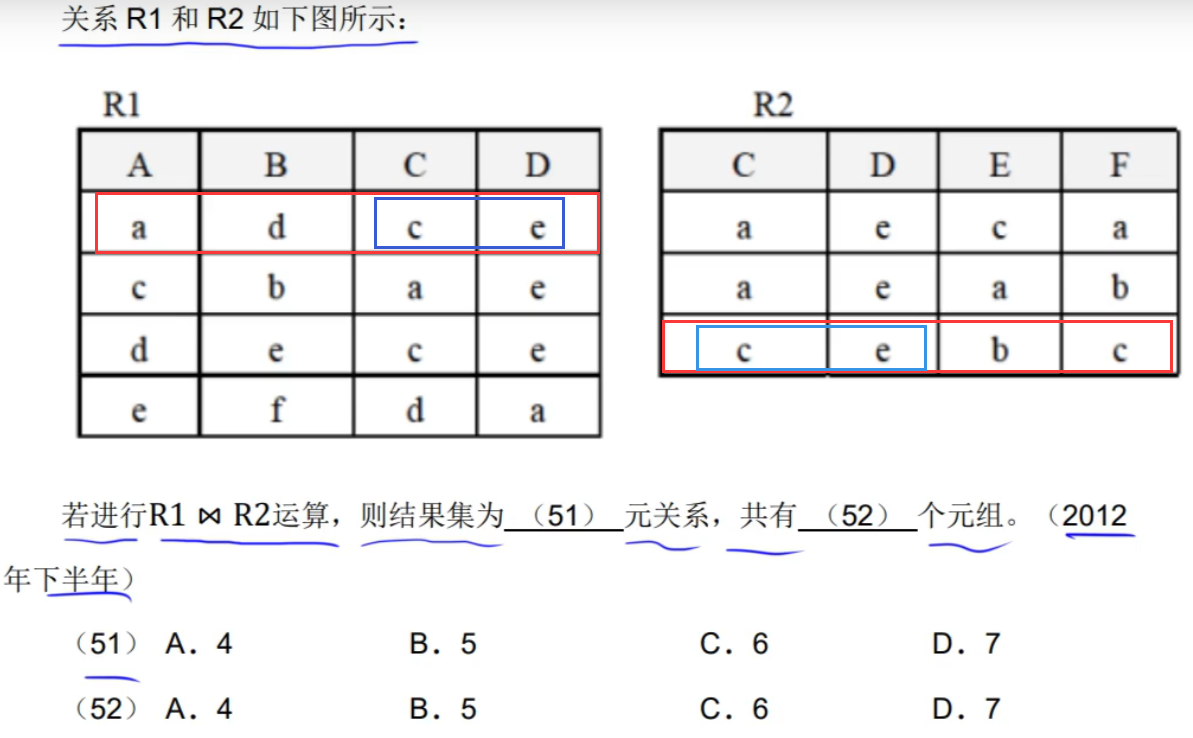
答案:(51)C (52)A
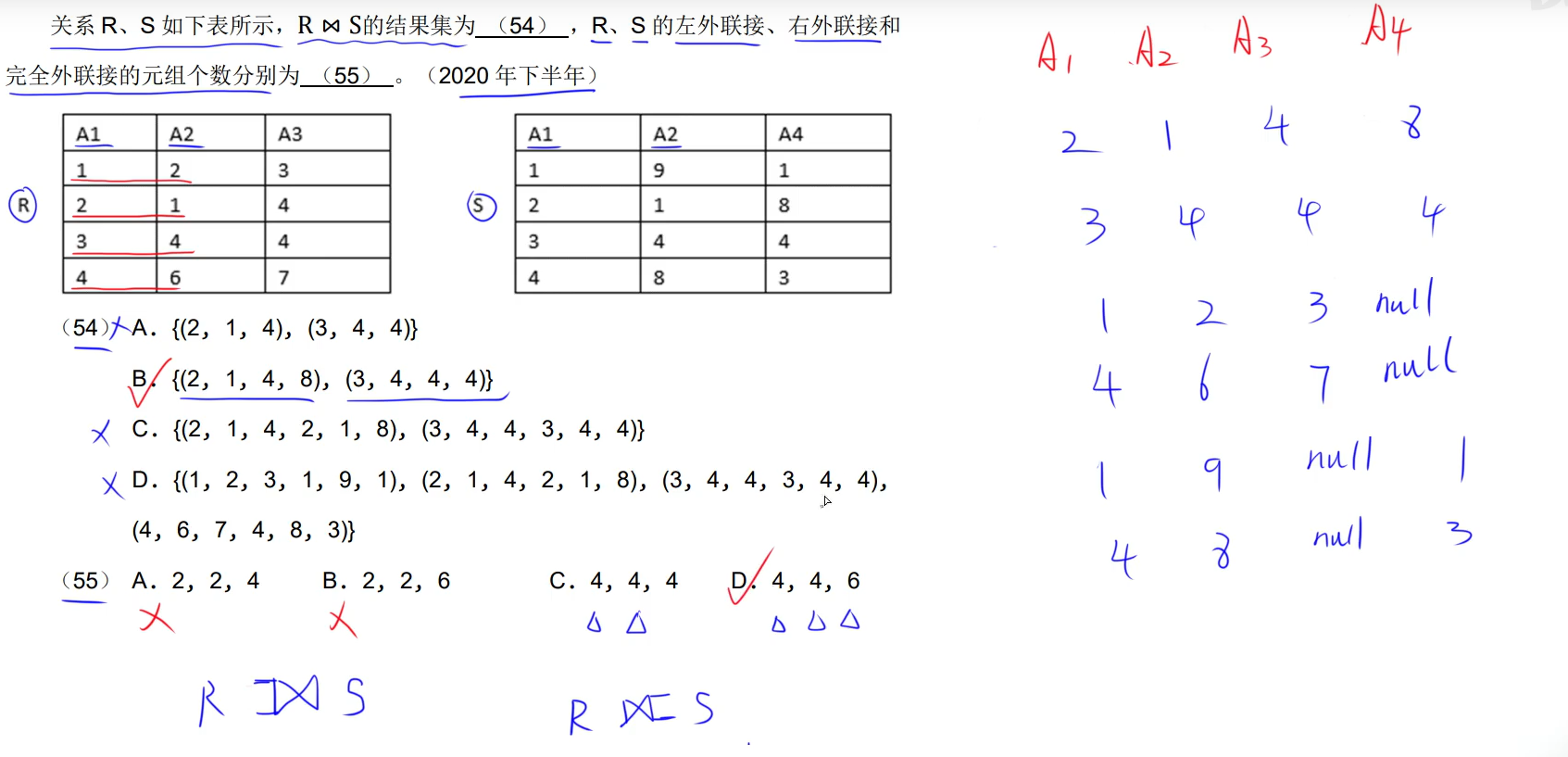


左外连接 右外连接

答案:D



3.5 完整性约束


实体完整性就是主键不能为空,参照完整性就是一个表的外键它可以为空,但是它必须要在另外一个表中找的到
3.6 关系代数转SQL语句
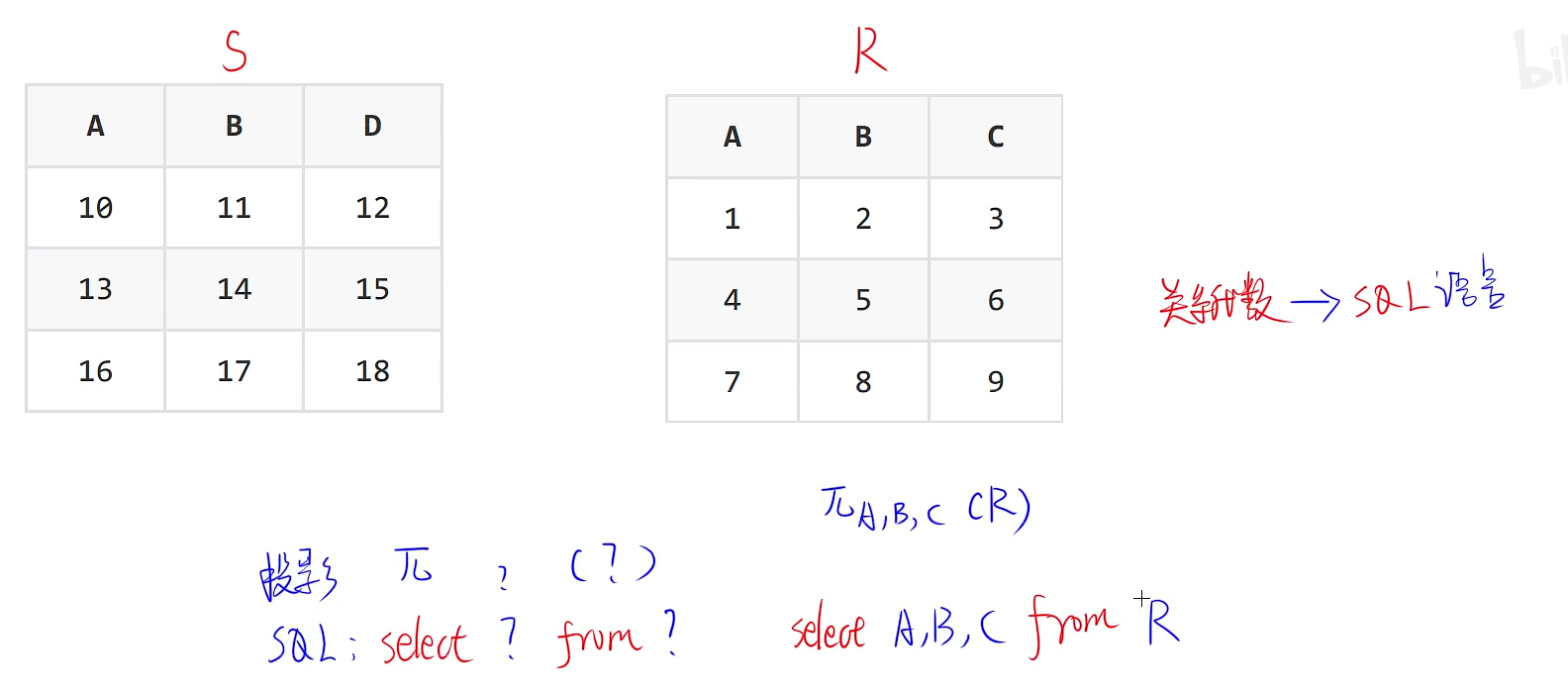
投影转SQl语句
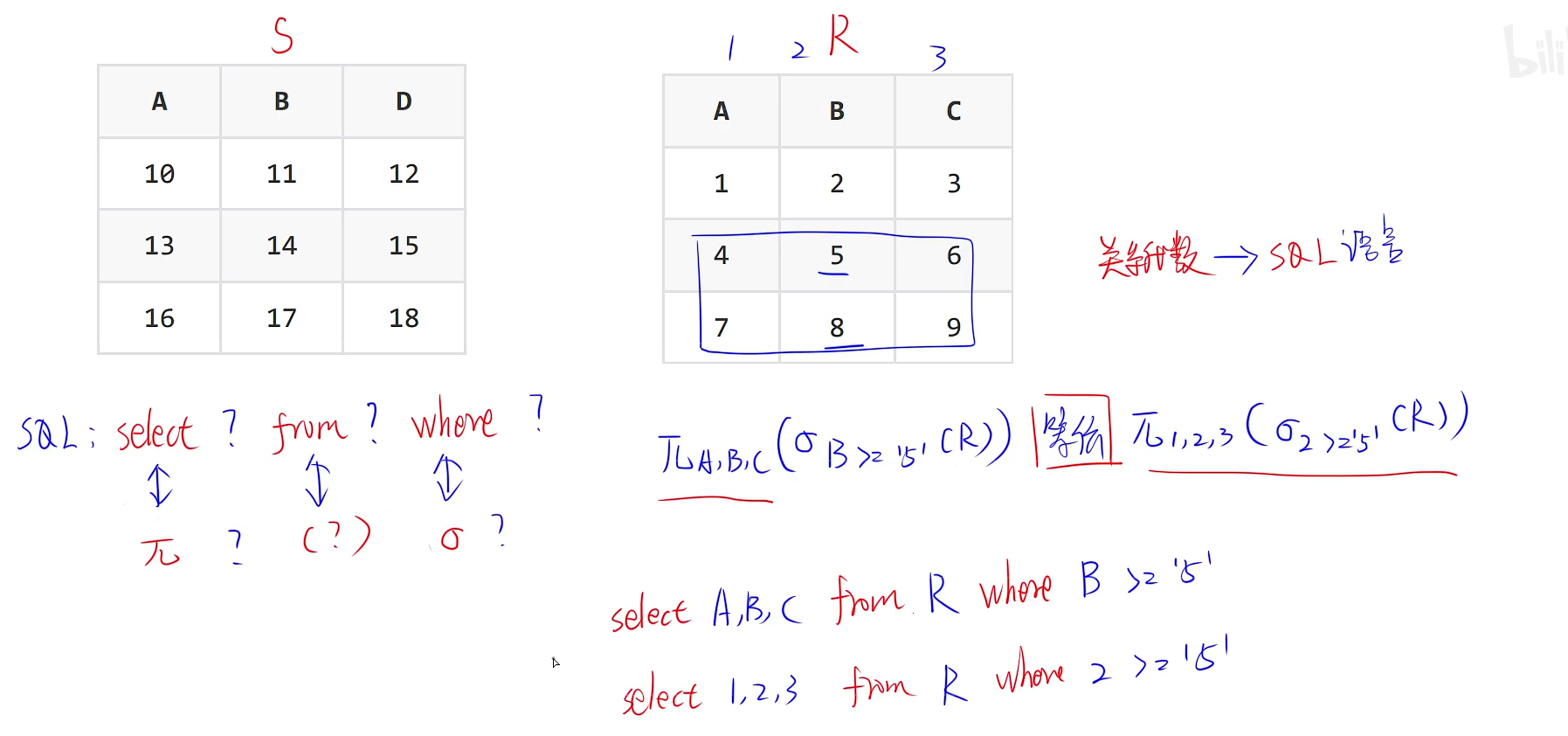
选择转SQl语句
笛卡尔积转SQl语句

自然连接转SQl语句

先把它的关系代数变形为上面等价的笛卡尔积表达式,然后在转SQL
真题


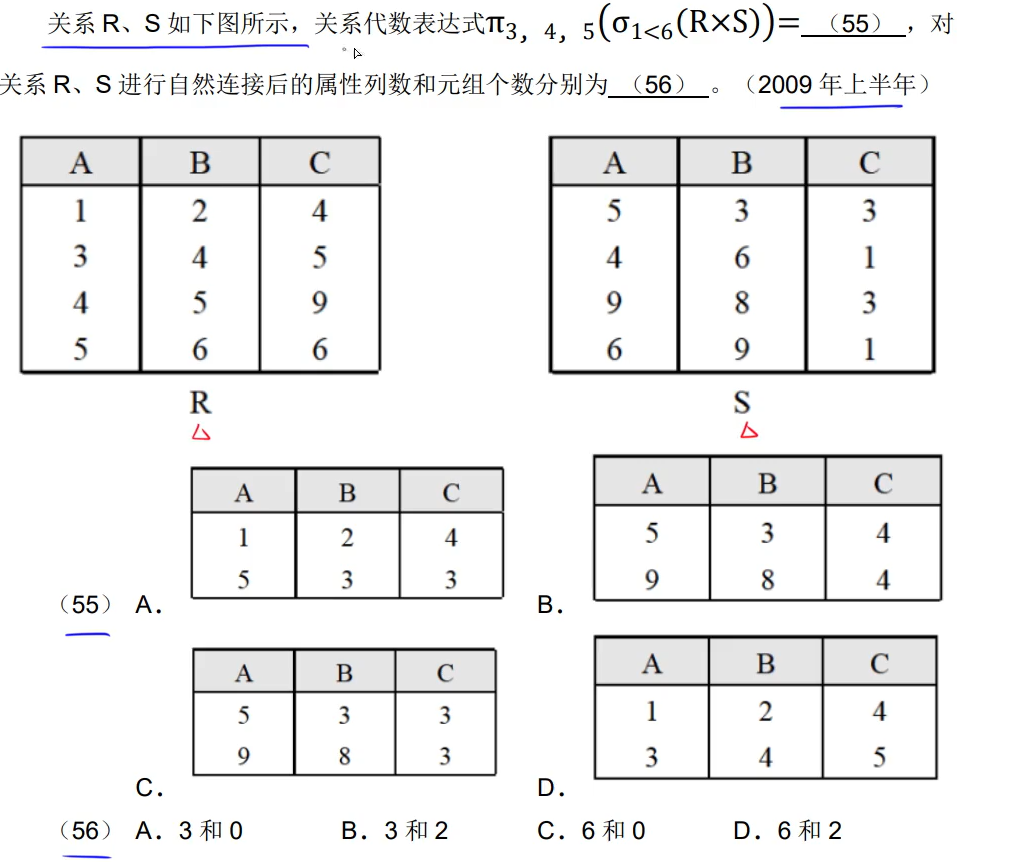
答案是C D B


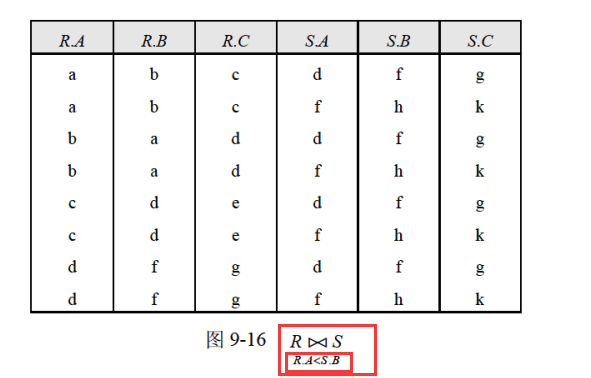
总结:做这样的题目第一要细心看清楚列号对应的属性,第二看清楚是R×S还是R⋈S,如果是R⋈S的话那就要去重
4、关系型数据库的规范化
4.1 关系模式


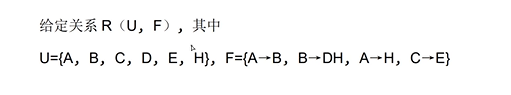
U为属性组,F为属性组U的一组函数依赖,箭头可以理解为决定的意思,例如学号—>姓名,可以理解为学号决定姓名
4.2 函数依赖


- 完全函数依赖:X - > Y , 则X的任意真子集都不能决定Y
- 传递依赖:
X -> Y , Y -> Z , 则 X -> Z
4.3 码和推理规则

主属性:候选码中包含的属性
4.4 属性闭包计算(求主键)
如果只有一个候选键那就是主键,有多个候选键那就挑一个做主键
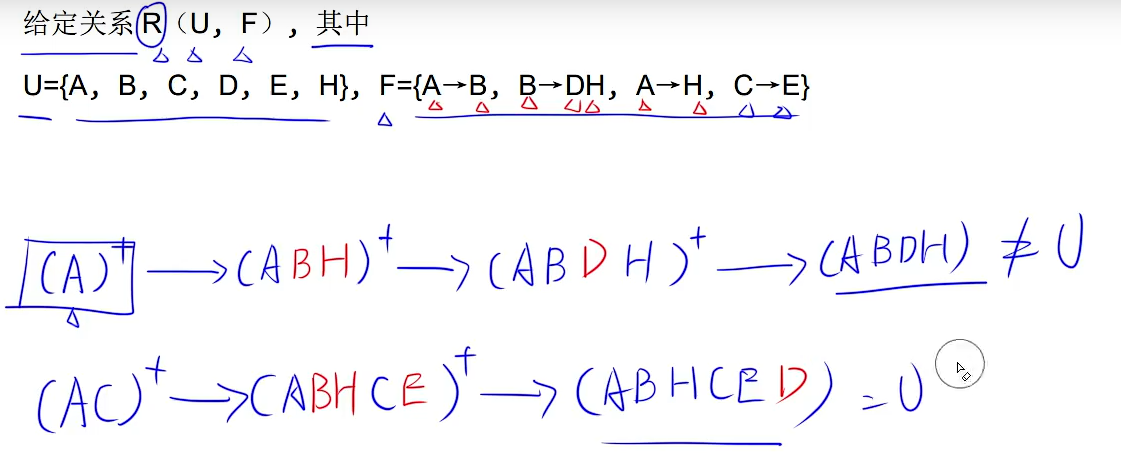
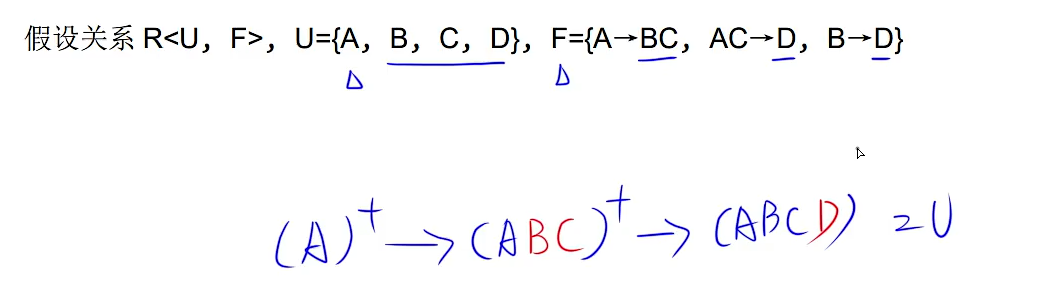
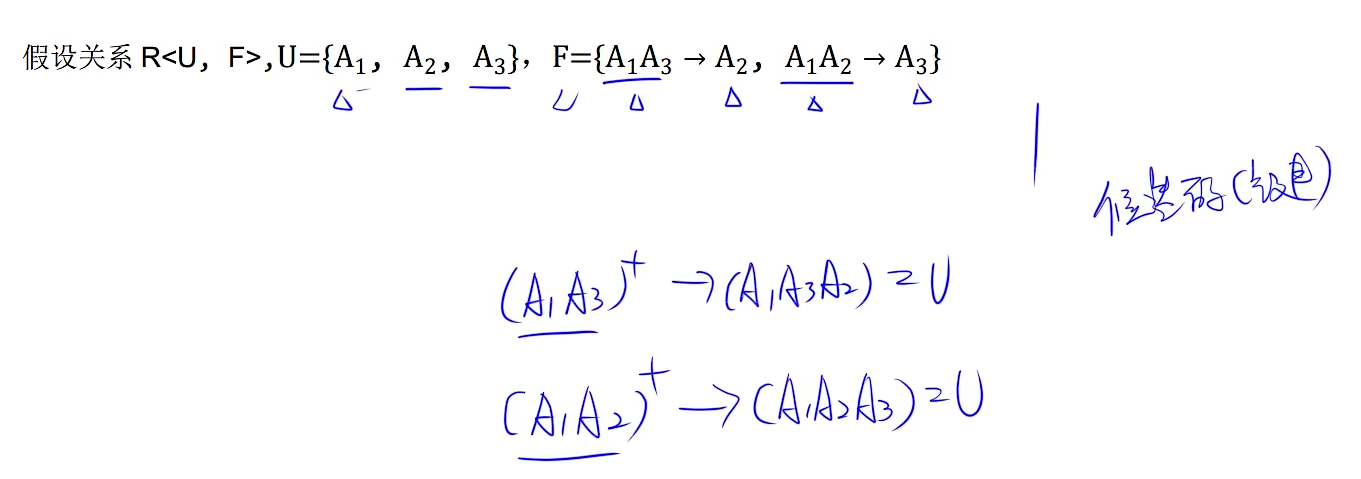
如果函数右边没有U中的属性,那么候选关键字中一定有它

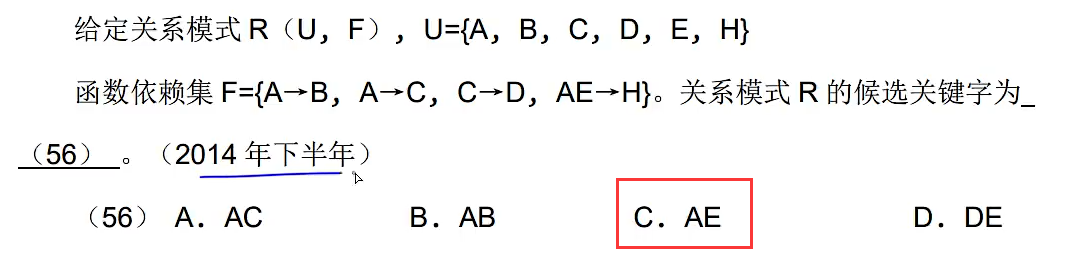

某个关系的主键为全码,那这个关系的主键就是它所有属性组合在一起


候选码:若k -> u ,则 k 的任一真子集 k’ 都不能决定U



第二题中用到了那个推理规则,A–>BC那么就可以得出A–>B,A–>C,这是分解法则



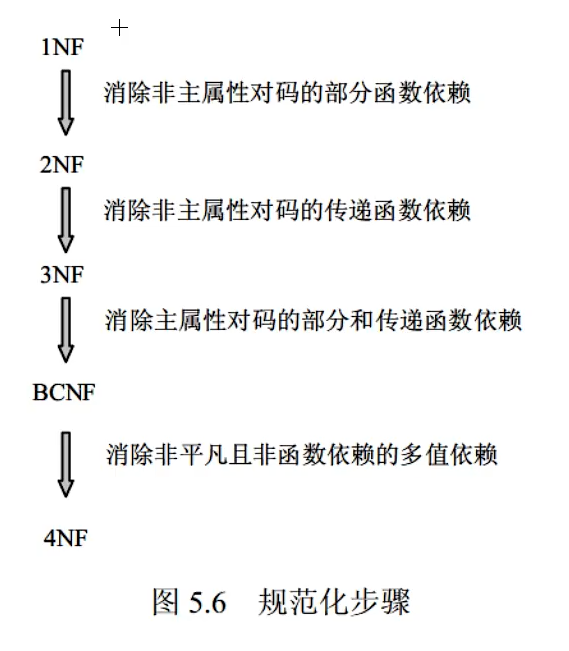
4.5 规范化
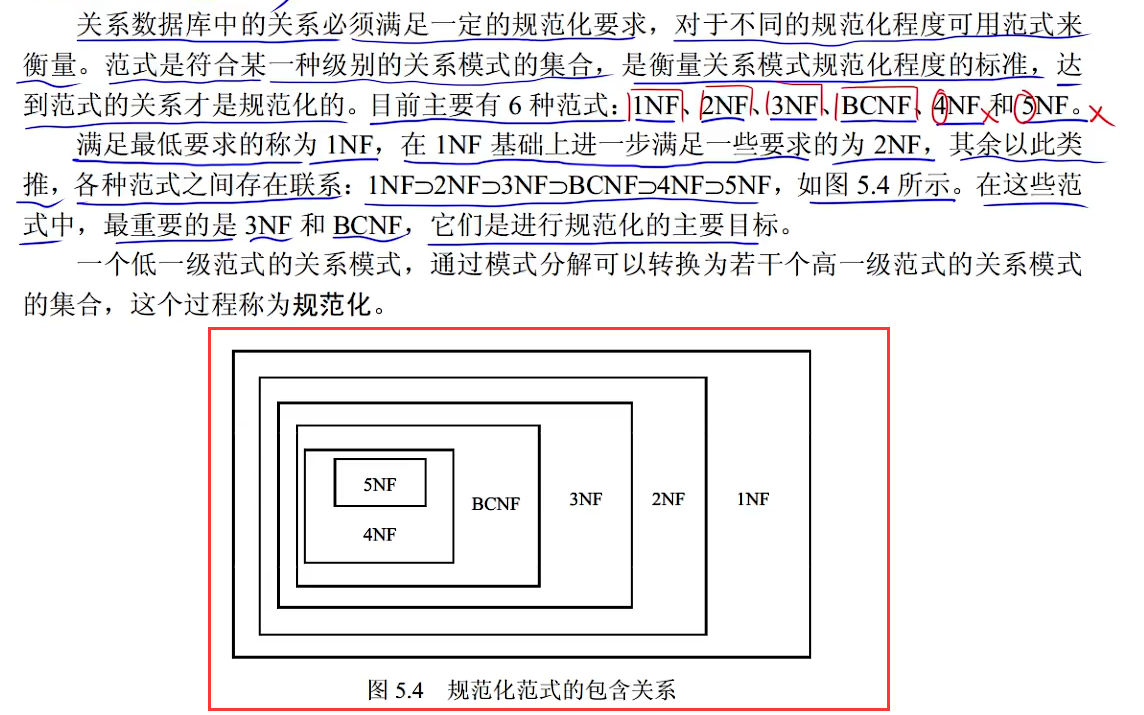
第二范式一定满足第一范式,第三范式一定满足一二范式,以此类推
第一范式
每隔属性都是不可分割的原子项

第一范式存在的问题
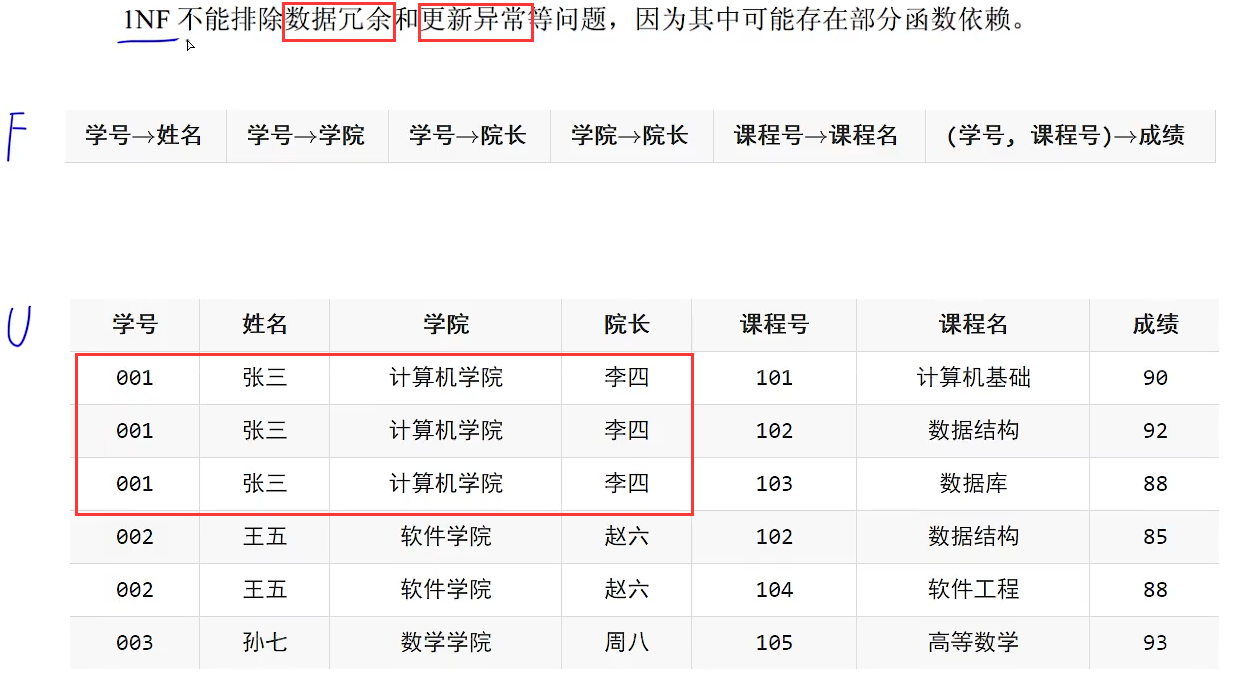
数据冗余容易理解,例如上图画出来的可以看出是内容是一样的,那就重复了很多次这就是数据冗余
更新异常中的修改异常,好比修改红色框中的张三为张四,那就必须把所有的张三都改成张四,如果只改一条就会出现问题,查询学号为001的数据的时候那姓名可能是张三也可能是张四,这就是修改异常
更新异常中的删除异常,好比删除高等数学这个课程名,但是上面这个表中要删除高等数学这个课程名那整一条数据都会被删除掉,也就是孙七这条记录都删除了,而我只是想删除这个课程,这就是删除异常
更新异常中的插入异常,好比我只是想要插入一个学生的信息是插入不成功的,因为上面这个表中主键是学号和课程号,由于主键的完整性约束,不能为空或部分为空,无论是单独插入学生信息还是单独插入课表信息都是插入失败,必须两个都插入才能成功,这就是插入异常
第二范式
非主属性完全函数依赖于候选码

第二范式是在第一范式的基础上解决了部分函数依赖的问题得来的,第二范式要求每个非主属性都完全依赖于候选键,上面的例子中候选键是学号和课程号,所以学号和课程号都是主属性,其他的都是非主属性,例如姓名是非主属性,由于姓名是由学号决定的,跟课程号毫无关系,所以姓名只是部分依赖于候选键,因此不符合第二范式的要求,但是符合第一范式

第三范式
非主属性都非传递函数依赖于候选码

第三范式只是解决了第二范式的传递函数依赖问题,但是数据冗余和更新异常没有完全解决,因为存在主属性对候选码的部分依赖和传递依赖
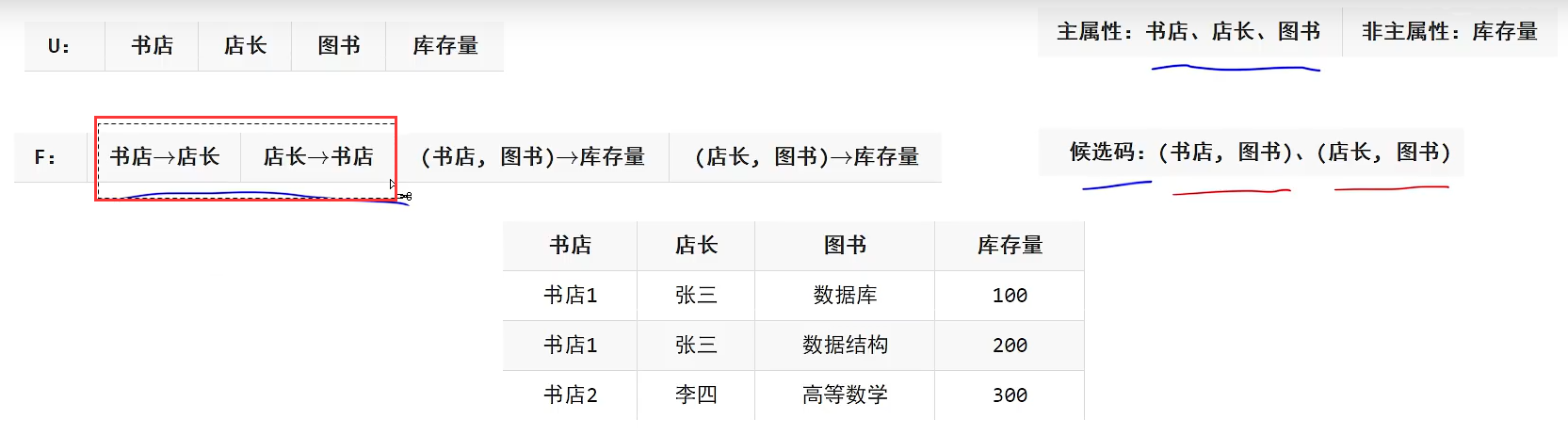
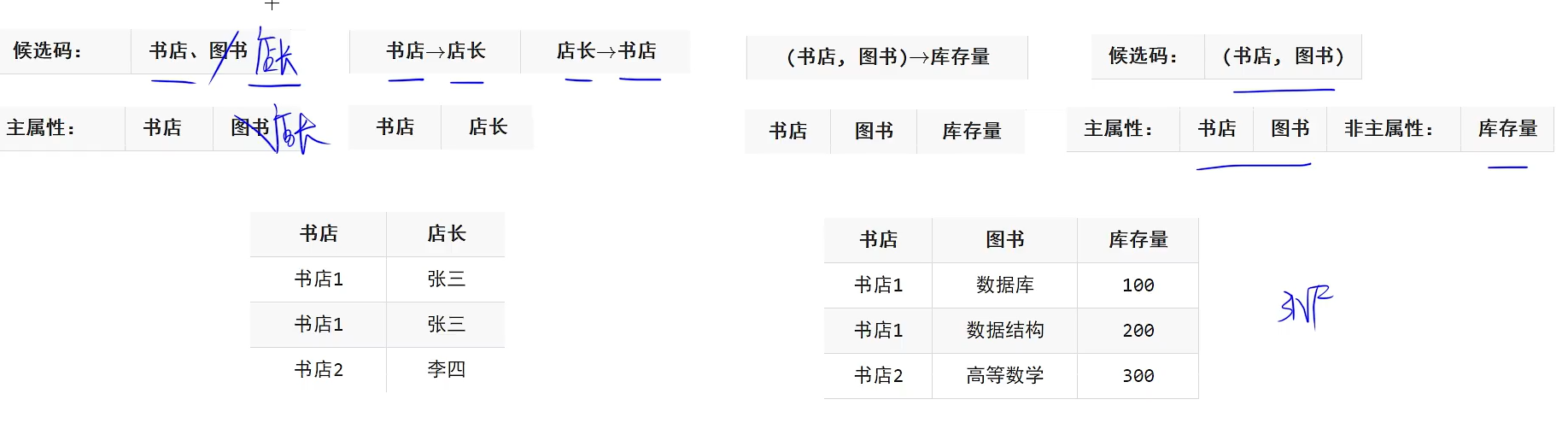
例如上图就是存在主属性对候选码的部分依赖这个问题,在F函数关系依赖中,红色画出的就是存在主属性对候选码的部分依赖的问题,因为候选码是(书店和图书)。而它书店就能够推出店长,跟图书没啥关系,所以存在部分依赖
BC范式

BC范式是在第三范式的基础上解决了存在主属性对候选码的部分依赖和传递依赖这个问题,同时还消除了插入和删除异常,下面就是把上面的表再进行分解,解决了存在主属性对候选码的部分依赖和传递依赖这个问题从而到达了BC范式
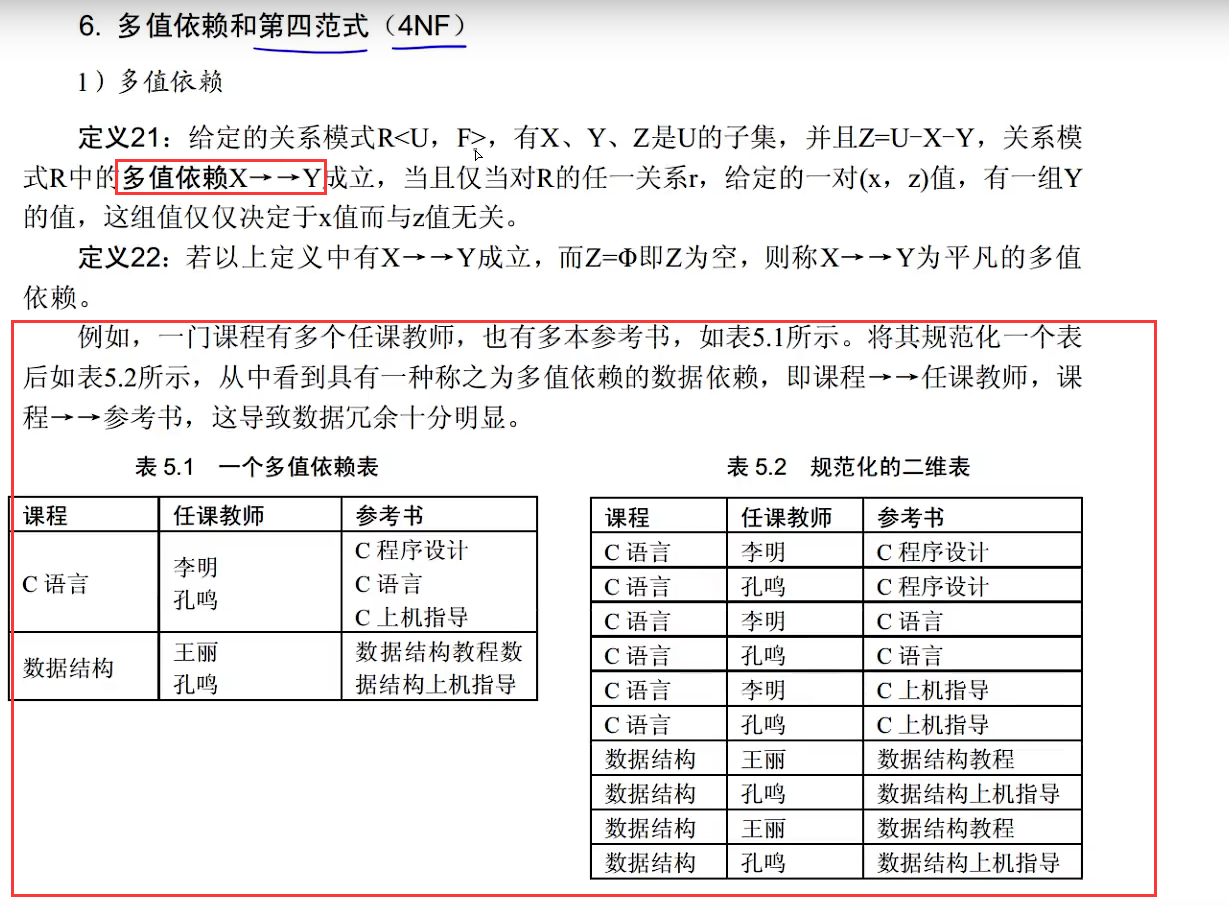
第四范式
消除非平凡且非函数依赖的多值依赖

总结
1、一般软考中的相关题目是都符合第一范式的,不需要考虑
2、判断非主属性是否对候选键存在部分函数依赖,说白了就是看非主属性能不能只靠候选键的一部分就可以推理出来(靠候选键组合中任意一个主属性就可以推出那个非主属性的就不是第二范式,但是如果是组合中其中一个和其他非主属性组合在一起推出非主属性的那就没问题)
3、看有没有传递依赖,存在传递依赖不符合第三范式
4、看主属性对候选码有没有传递依赖或部分依赖,也就是主属性可以由候选码中任意一个就推出来那就不符合BCNF范式
5、看有没有多值依赖,并且多值依赖的左边是码,例如A->B,A->C,并且A是码,那就符合第四范式
做题技巧

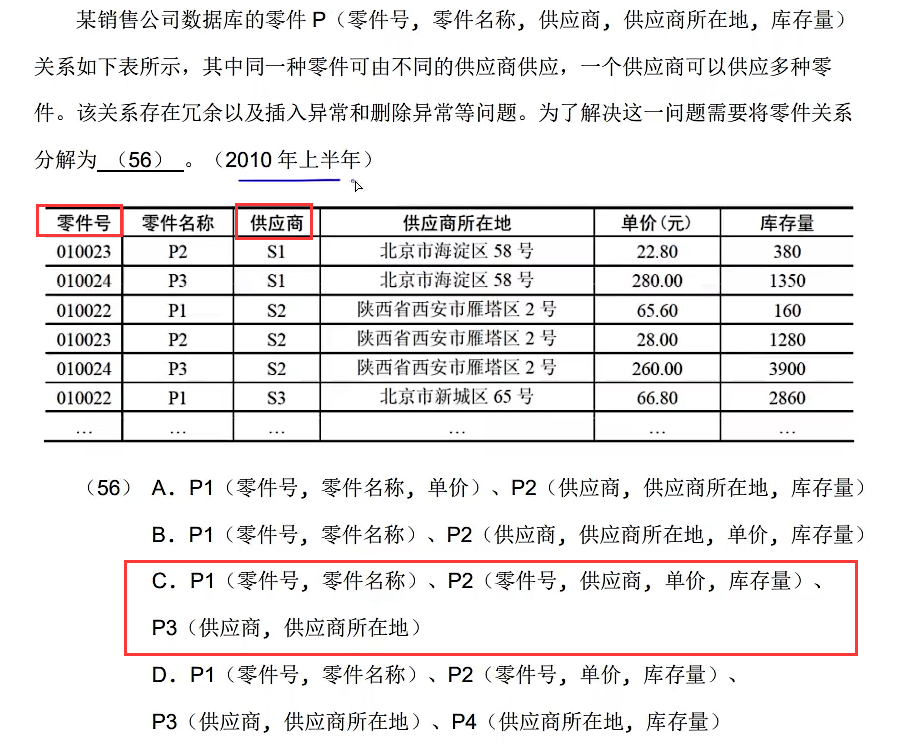
首先知道软考的相关这类题都是符合第一范式的,所以可以直接判断是否符合第二范式,判断第二范式首先要知道这个关系的候选键是什么?这是为了知道哪些属性是主属性?哪些是非主属性?这个例题中零件号和供应商的组合属性是候选键,所以主属性是零件号和供应商,其他都是非主属性,然后判断非主属性是否对候选键存在部分函数依赖,说白了就是看非主属性能不能只靠候选键的一部分就可以推理出来(靠候选键组合中任意一个主属性就可以推出那个非主属性的就不是第二范式,但是如果是组合中其中一个和其他非主属性组合在一起推出非主属性的那就没问题),例如零件名称是非主属性,根据函数依赖关系,零件号–>零件名称,可以看出这个非主属性只需要零件号就能推出来,跟候选键中的供应商没屁关系,所以就是存在部分依赖,不符合第二范式!所以是第一范式!

候选码是EM,所以主属性是E和M,非主属性是N,Q,L,然后去函数依赖集里看**非主属性能不能只靠候选键的一部分就可以推理出来,**发现E可以直接推出N,不需要M,也就是我所说的只靠候选键的一部分就可以推出某个非主属性,所以不符合第二范式,应该是第一范式!

候选键是学生和时间的组合,主属性就是时间和学生,非主属性就是课程,教师,成绩,教室,这些非主属性都不能由候选键的部分推理出来,所以符合第二范式,然后在判断符不符合第三范式

这里由于存在传递函数依赖,所以不符合第三范式,挺难搞的这个题,它用到了伪传递原则,然后可以推理出(时间,学生)时间–>课程这个关系,由于这两个时间是一样的所以去掉一个后最终是(时间,学生)–>课程,然后课程–>教师,所以得到(时间,学生)–>教师,这是传递函数依赖,因此不符合第三范式,所以可以看出其实就是把那些关系通过那些原则去变形,挖掘其中隐藏的关系,看看有没有存在传递函数依赖的,有就不符合第三范式
真题

这里我是看存不存在主属性对候选码的部分依赖或传递依赖来判断能不能达到BC范式,对于R2关系来说,主属性是学生和课程,非主属性是成绩,候选键是学生和课程的组合,可以看到候选键中是包含主属性的,所以不存在主属性对候选码的部分依赖,就一个函数关系依赖,也不存在主属性对候选码的传递依赖,所以满足BC范式,第四范式主要是看存不存在多值依赖,所谓的多值依赖就是一个属性决定很多个其他属性,例如A–>B,A–>C,A–>D,这里一个A决定了BCD三个属性,也就是多值依赖





这里分享一个判断第二范式的技巧,找到主属性A2和A5后,那么其他都非主属性都知道了,直接看非主属性是怎么得到的?如果是由单独的一个A2或A5就能得到那就不符合第二范式的要求,例如上面题目的A1是由A5和A6一起得到的,所以这个A1是不存在部分函数依赖的,如果说上面关系中有A5–>A1,那就存在部分函数依赖,同理,再看A3是由A1得到的,跟A2和A5没屁关系,所以也不存在部分函数依赖的,总之,只有非主属性是靠单独的一个主属性就能推理得到的那就是存在部分函数依赖,不符合第二范式,其他都是不存在部分函数依赖的
4.6 关系分解
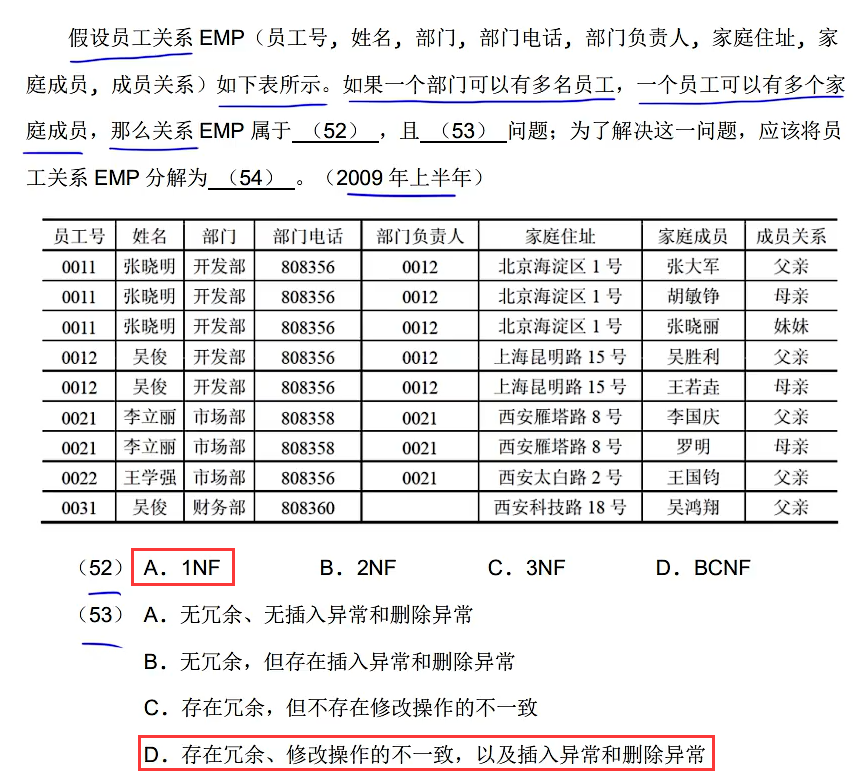

这个题目跟前面做的不一样,它并没有给函数依赖关系,而是直接给了个表,首先不要慌,可以看到每一列都有重复的,所以一定是一个组合的候选键,这里选员工号和家庭成员组合为候选键,为什么不选成员关系呢?因为成员关系中可能会有多个兄弟姐妹,所以主属性是员工号和家庭成员,然后姓名是可以直接由员工号推出,存在部分函数依赖,不符合第二范式,主要是分解表怎么分解?自己看视频去

4.7 无损连接和保持函数依赖



是否保存函数依赖就直接看分解后的两个关系中是否有原来函数依赖集的那些关系依赖,如果没有那就不保持!

判断是有损连接还是无损连接直接把分解后的关系作自然连接,看看得到的结果是不是跟原来的R一致,如果不一致那就是有损连接,否则无损连接**,在这里的自然连接就是把分解后所有关系的属性列合在一起去个重就可以了,例如上面的把分解后的两个关系中的属性列合在一起是A1A2A1A3,A1重复,去重后是A1A2A3,跟R对比少了A4,是有损连接,这里要注意自然连接是必须要两个关系有公共的属性自然连接才有值,否则就是空集,例如上面的都有公共属性A1,所以自然连接不是空集,但如果是(A1,A2),(A3,A4)这样的就没有公共属性,自然连接就是空集,如果多个关系自然连接,只要有一个自然连接结果是空集,那就整个关系自然连接的结果都是空集**

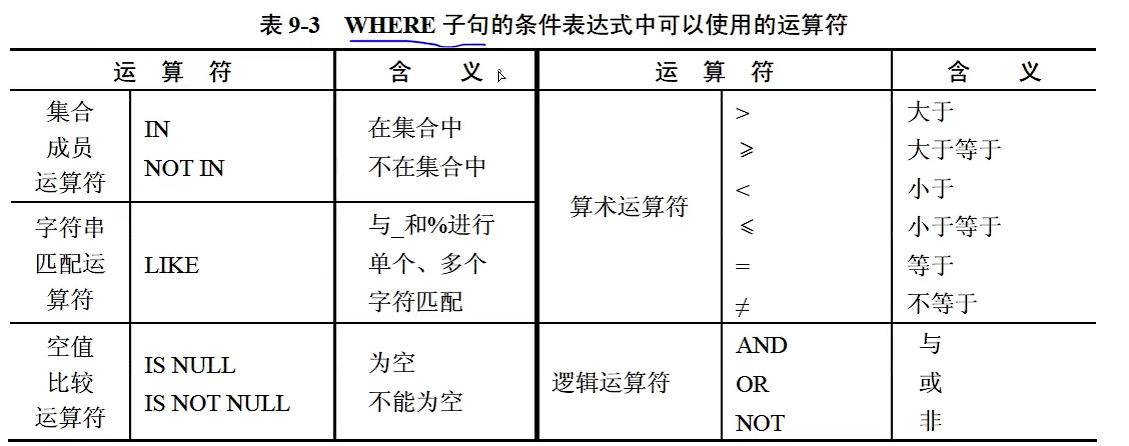
5、关系型数据库SQL语句
5.1 SQL语句的分类

5.2 数据定义语句(DDL)

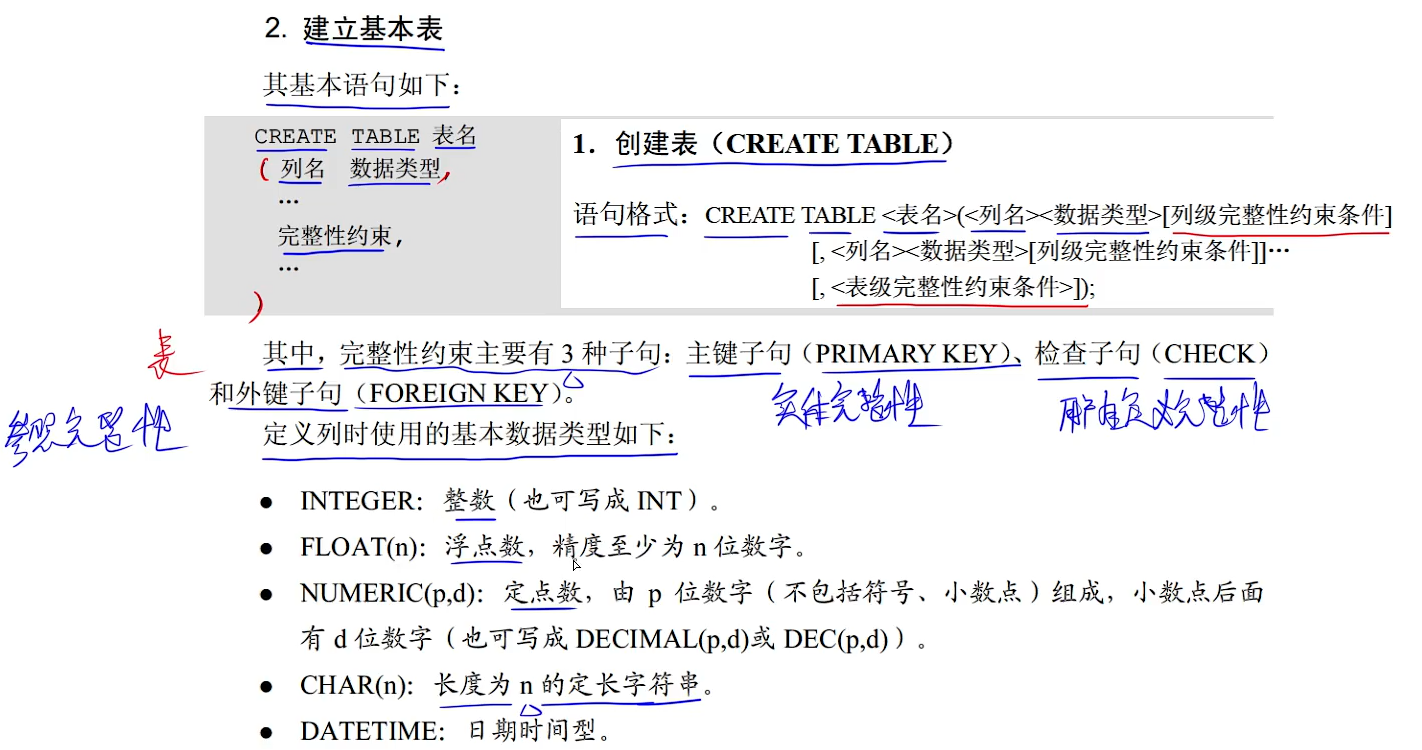


修改不是指的修改列的表名,而是指的修改列的类型,一般用上面modify来进行修改

列的完整性约束
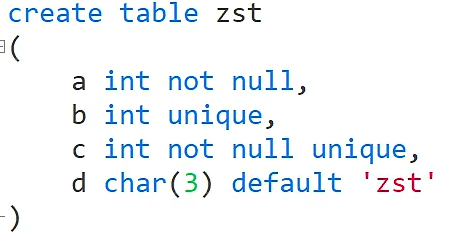
not null 是不能为空
unique 是不能重复(也就是唯一约束)
not null unique 是不能为空并且不能重复
default 是设置默认值
表的完整性约束
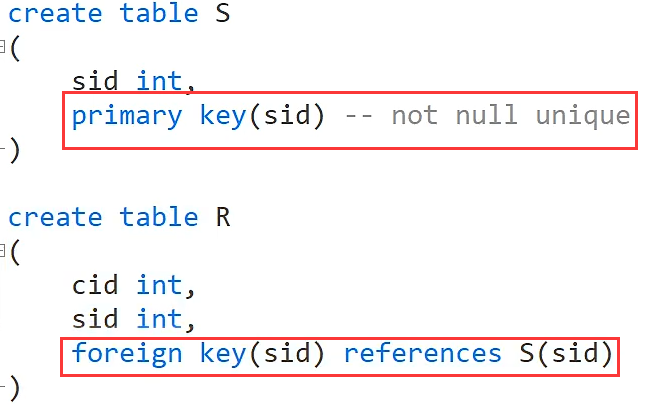
用户自定义完整性
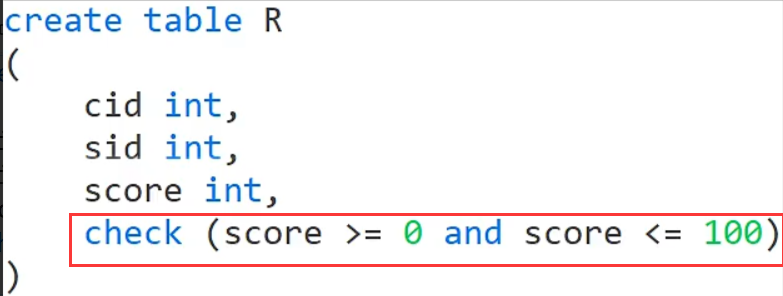
primary key是主键约束(功能和not null unique 一样)
foreign key是外键约束(上面的外键约束语句意思是对sid设置外键约束并且参照S表中的sid)
check 是用户自定义完整性约束(上面语句意思是检查成绩是否在0-100范围内,也就是在表中插入数据的时候成绩这一列会有一个自动检查成绩范围的约束,不在这个范围就会报错)
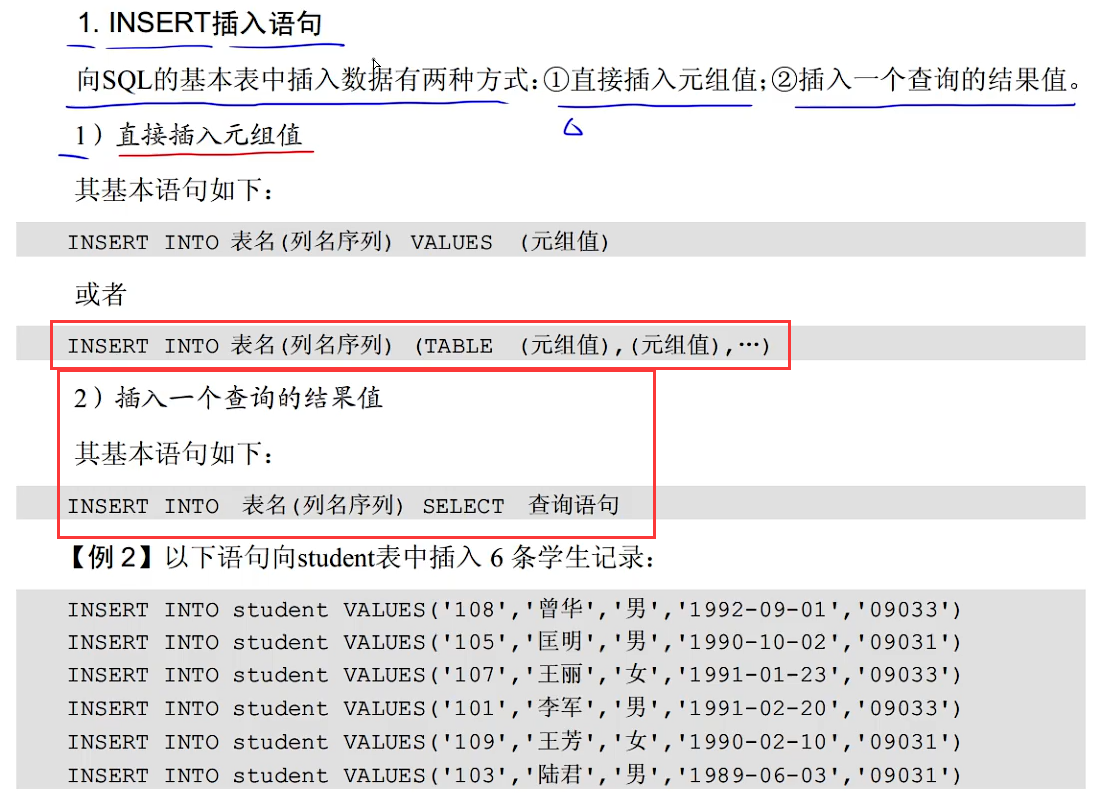
5.3 数据操纵语言(DML)

5.4 数据查询语言(DQL)

投影查询
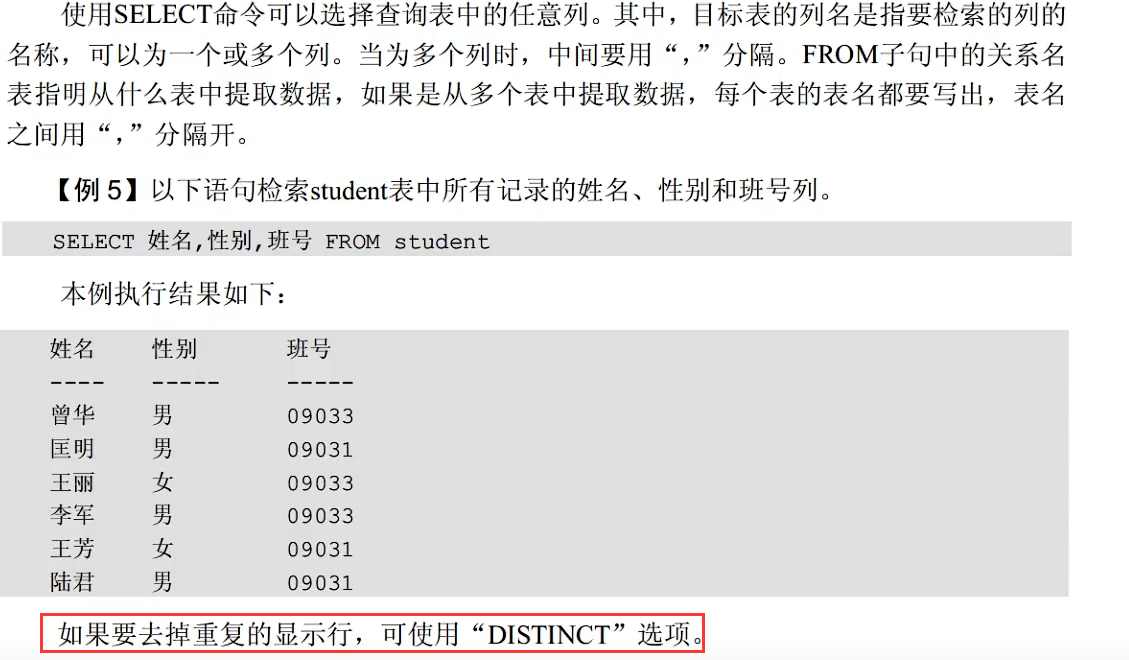

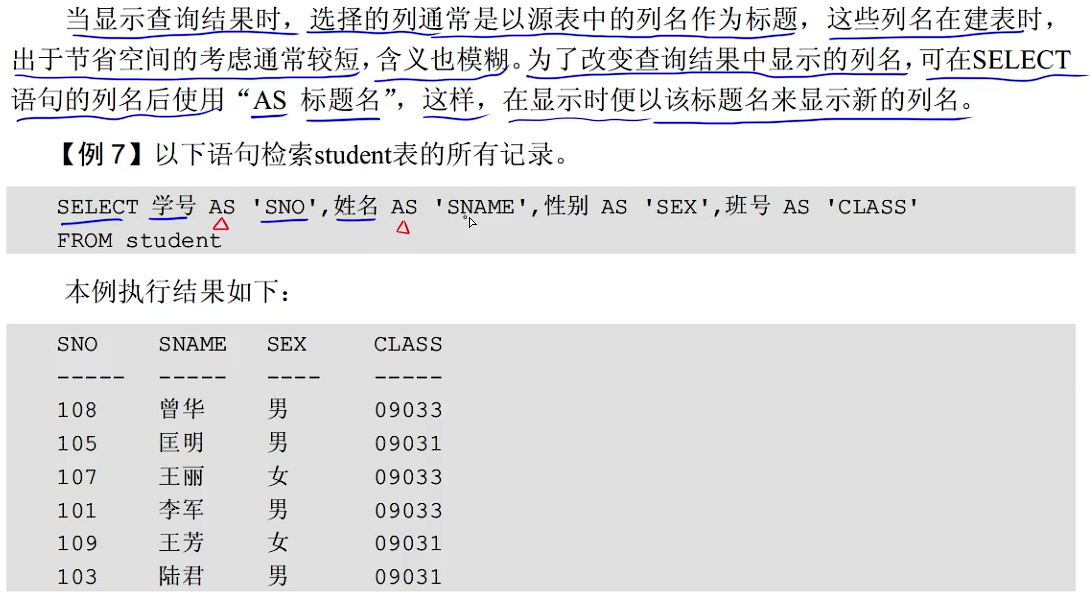
选择查询



排序查询

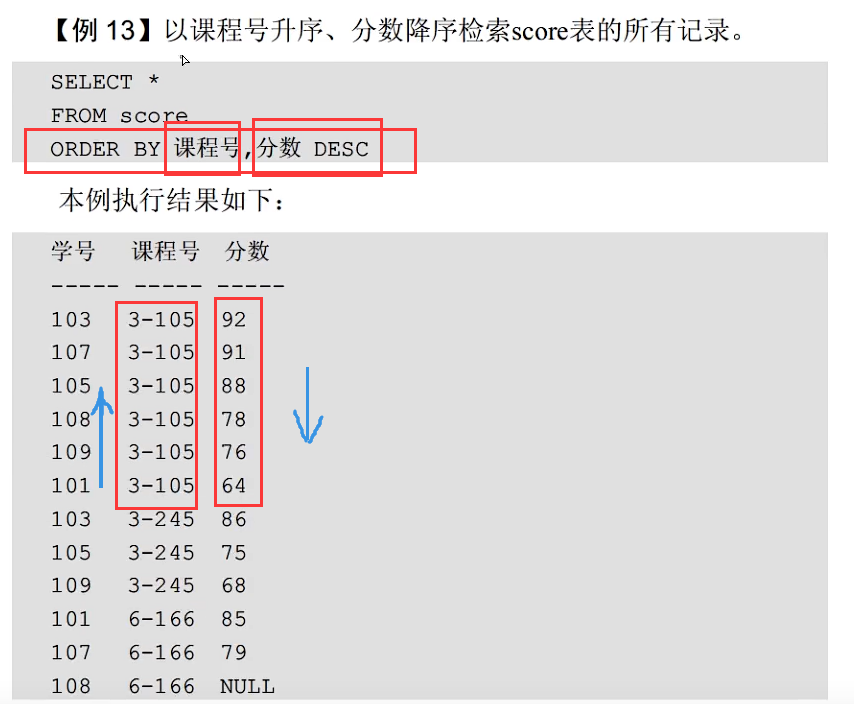
注意上面红色画出来的语句不是说课程号和分数都是降序排列,这里课程号没有指明是什么排序,那就是默认的升序,分数指明了是降序排序,但是这里是多条件排序,所以是先按课程号进行升序排序,如果课程号相同,那就按分数降序排序
聚合函数查询
(注意聚合函数只会返回一个结果值)
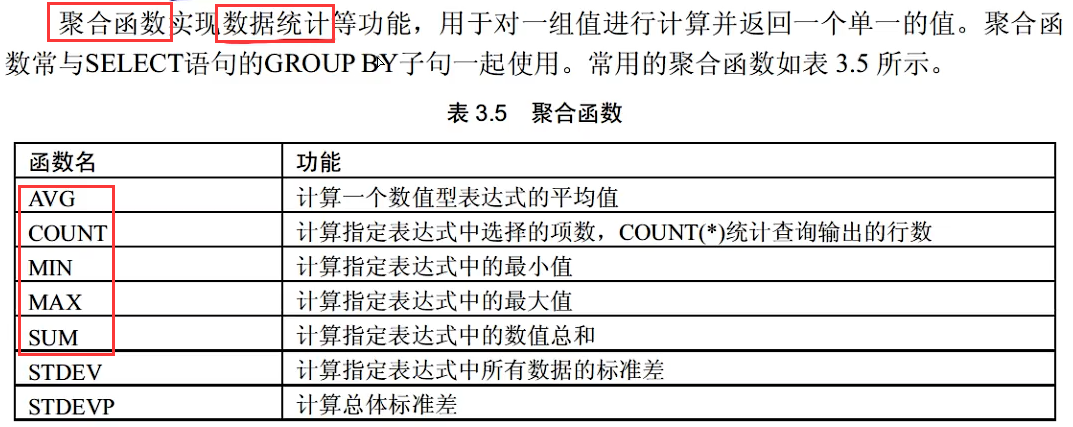
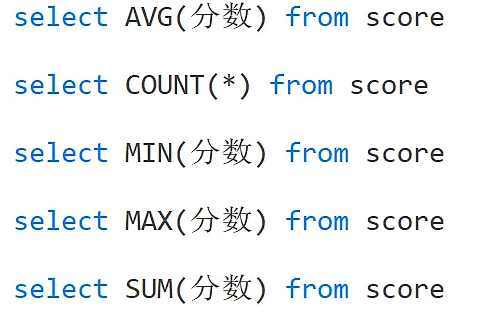

上面这句是验证分数的平均值,也就是AVG集合函数
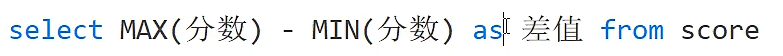
指的一提的是上面这样写是没问题的,可以进行加减乘除运算(这是我的知识漏洞)
同时要注意count(*)和count(列表名)的区别,区别就是count(*)会把null也算作一个值,会把null这条记录进行统计,而count(列表名)就直接忽视null的记录,不会把这条记录进行统计。

这是查询课程号的数量并且去重

数据分组

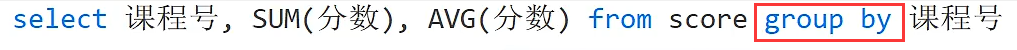
 分组后
分组后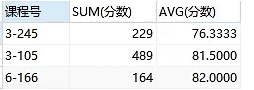
所谓的分组就是把属性值相同的分为一组,例如上面是按课程号分组的,那么课程号中相同的值就会被分作一组,分组主要用于聚合函数查询只能返回一个值,如果想看具体的情况就使用分组
这里要注意having和where的使用区别,区别就是如果拼接的条件里用到了聚合函数,那就只能用having,不能用where!



内连接


外连接
子查询(先子查询再主查询)
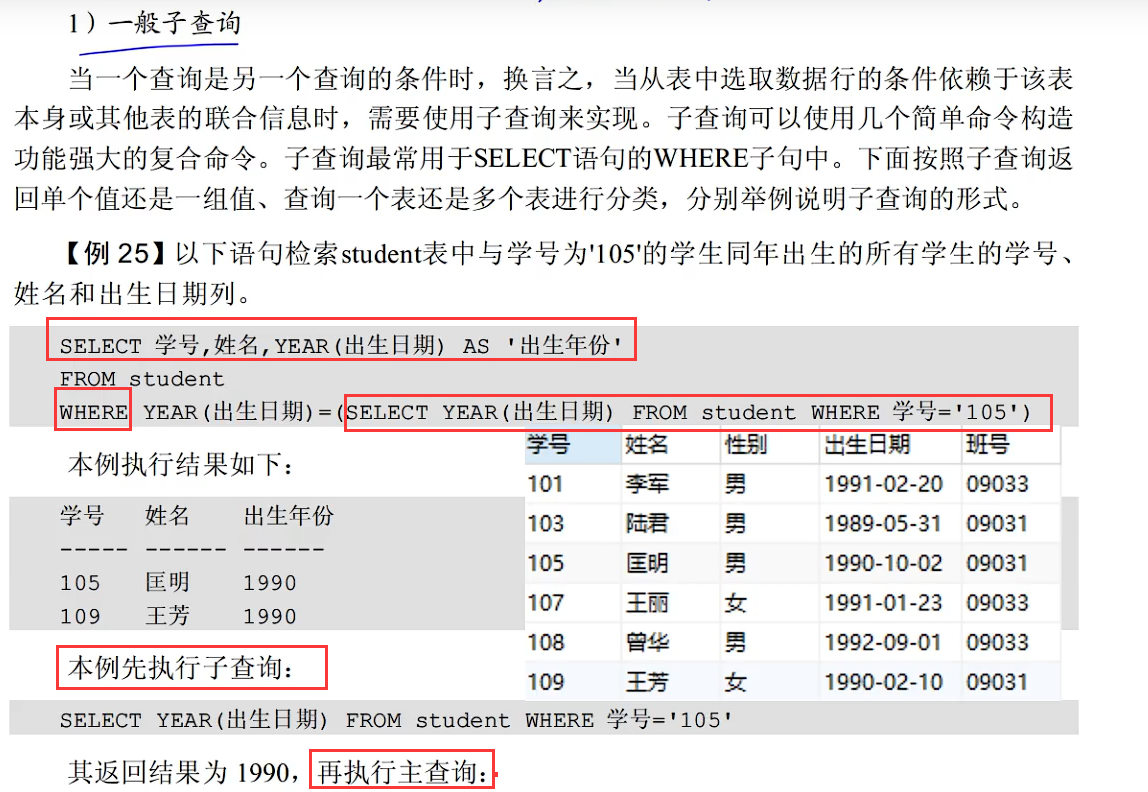
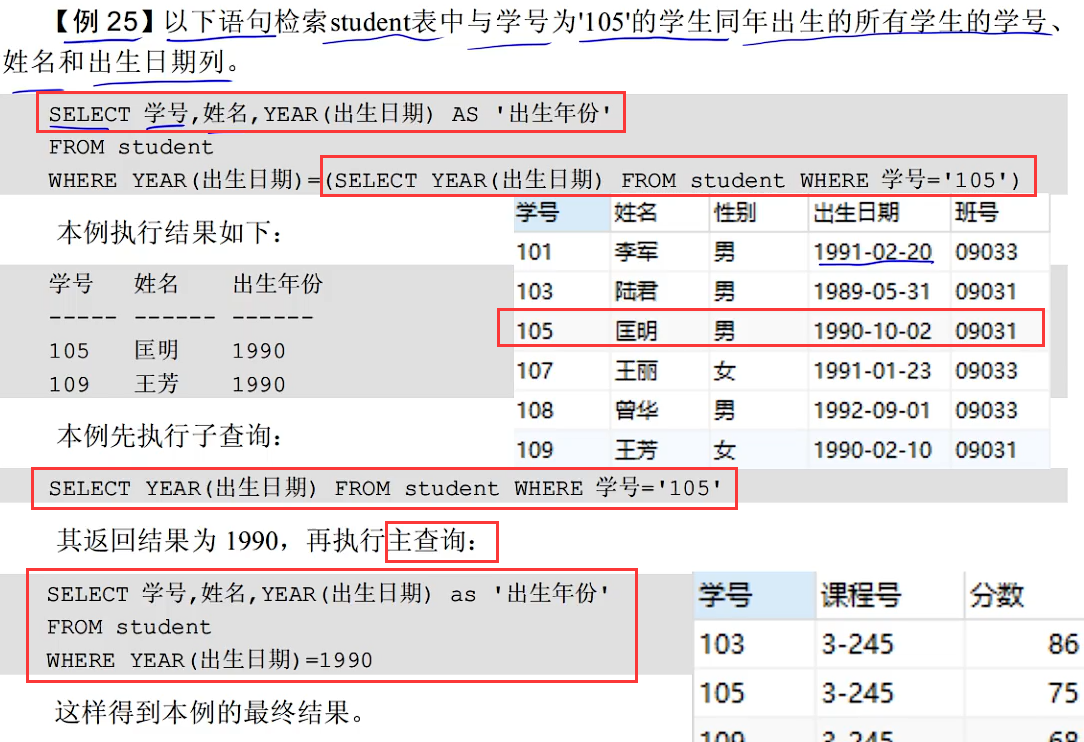


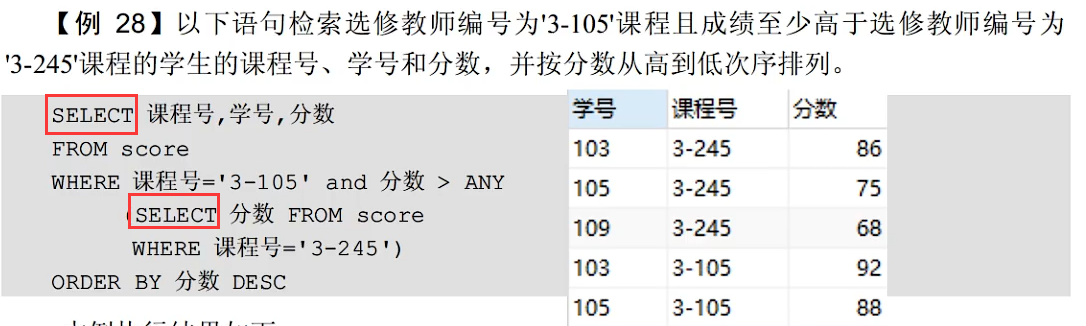
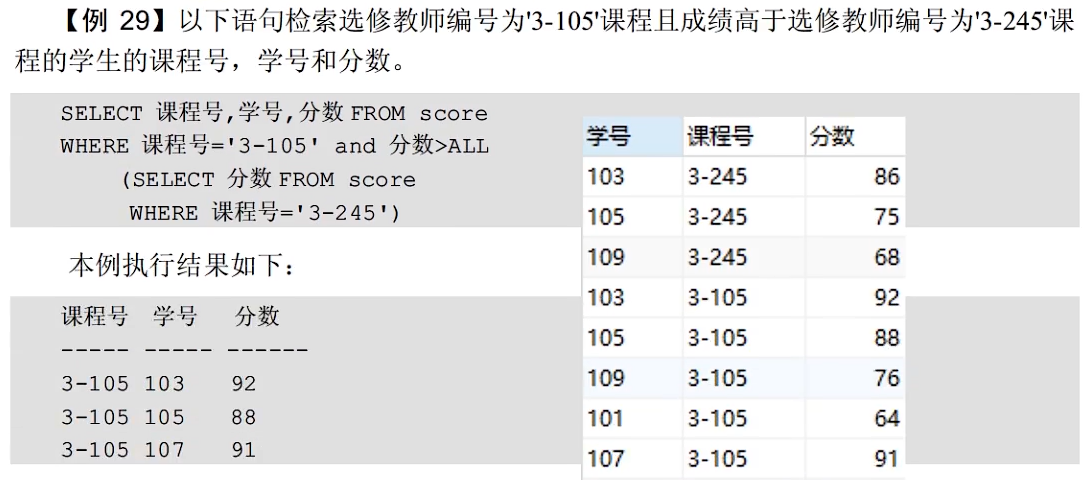


真题
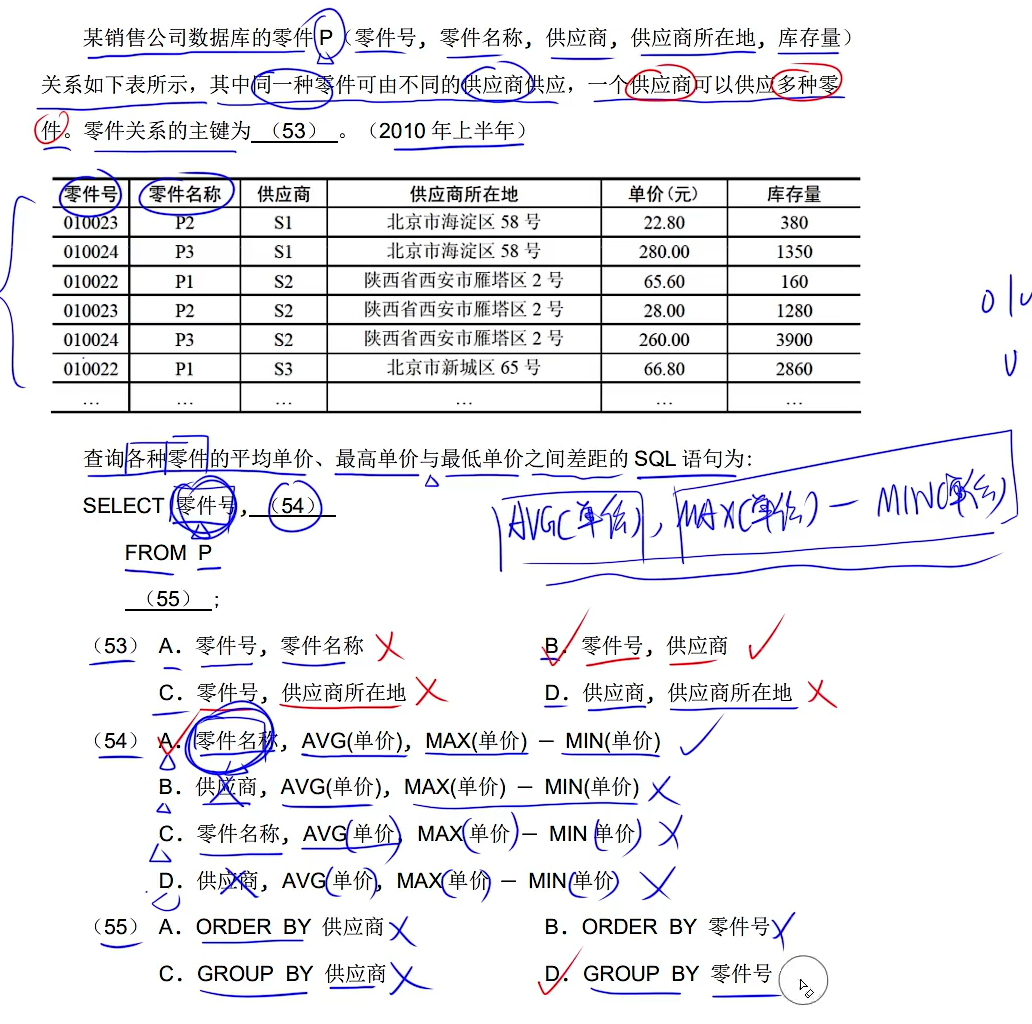



这里注意59题的3500是不要单引号引起来的,不要把这里和前面的选择6的条件搞混淆了,这里只有字符串才需要用单引号引起来,数值型是不需要用单引号引起来!
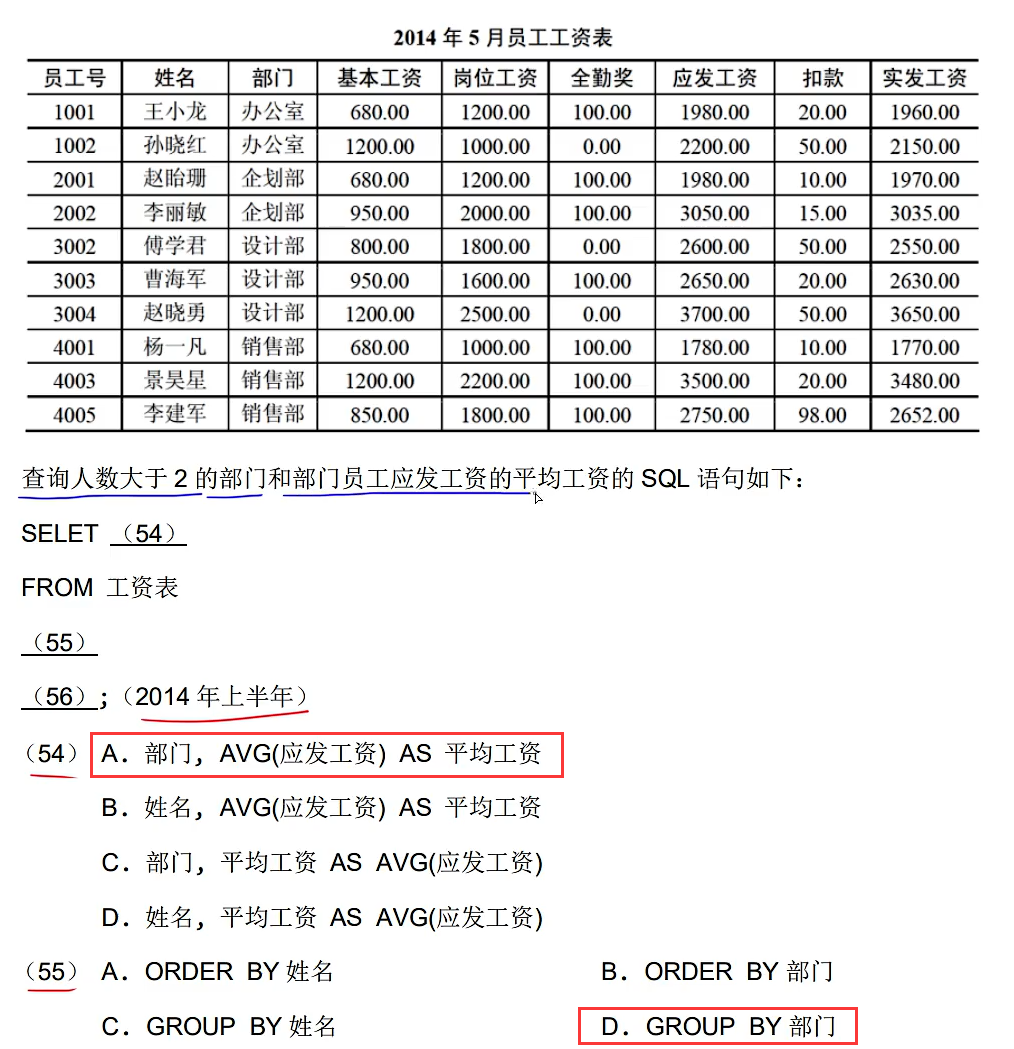

上面红色框出来的是正确答案,注意第56题的C和D选项,D选项是使用了DISTINCT关键字进行去重的,这里特别注意,由于这里使用了聚合函数所以用HAVING,其二由于分组了所以去重后每个组的结果数量都只会是1,例如上面D选项的结果就如下图所示,结果每个部门都是1,因为分组是把相同的分作一组,而相同的又会被去重掉,自然结果就是1
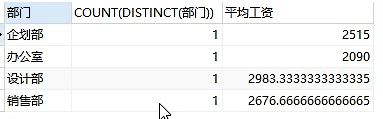
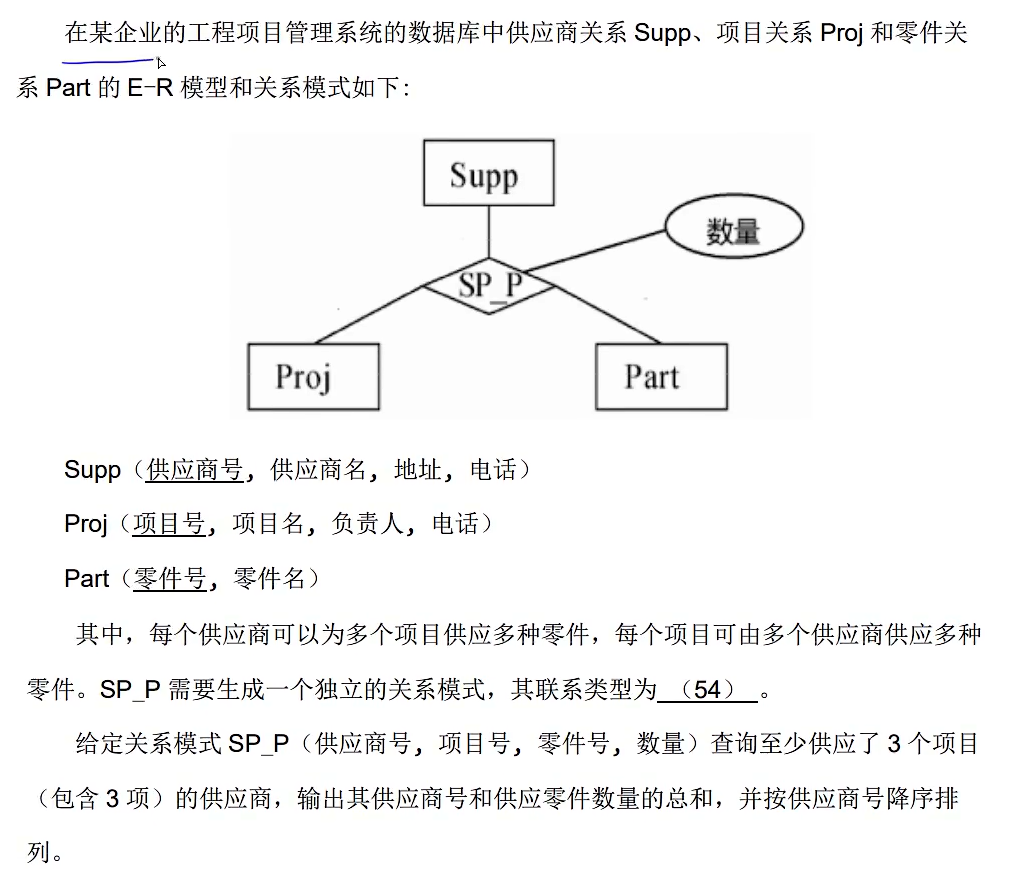

这里要跟真题3的56题区分开来,具体要不要去重要结合题意进行分析,真题3中员工和部门是一对多,不用去重,而这里项目和供应商是多对多,需要去重,因为同一个项目的同一个供应商提供多种零件,如果这时对项目属性进行统计就会大于1,也就是不去重的话结果是一定大于1的,单实际上只有一个项目
5.5 数据控制语言(DCL)
SQL访问控制
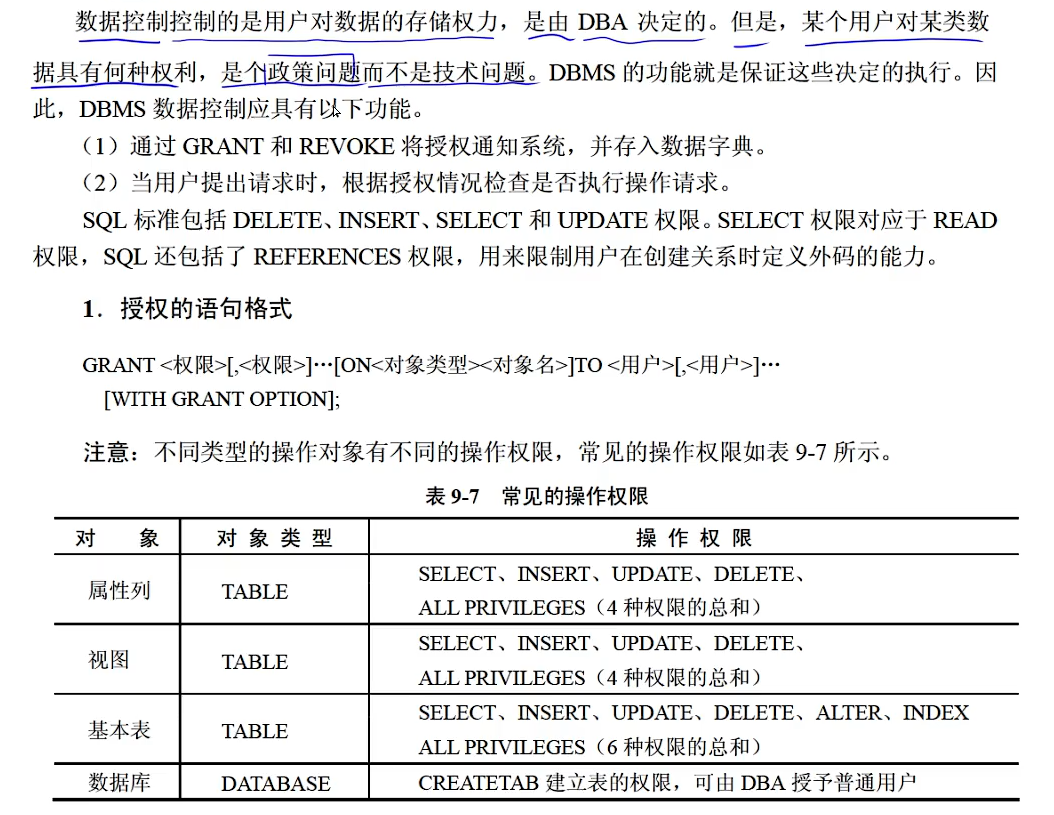

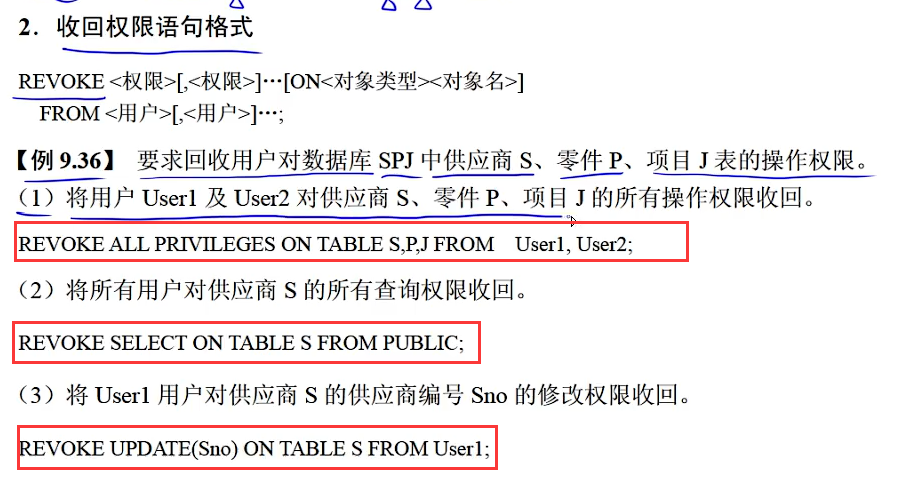
真题


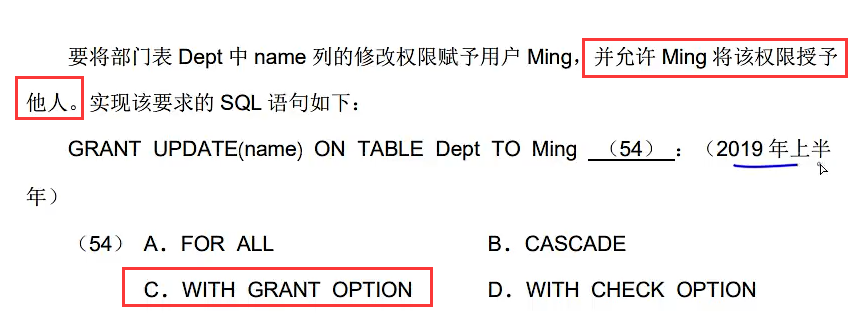
5.6 视图




这里注意视图它是虚拟表,对视图进行的增改操作实际上是对基本表进行操作,例如上面的创建student视图,它的基本表就是学生表(也就是这个视图是在谁的基础上创建的),然后在视图中插入不符合where后面的条件的数据,视图里不会新增这条数据,这条数据会新增到基本表中去,如果符合where后面的条件,那这条数据会到视图中去,这样就确保了视图中的数据都是符合where后面的条件的数据,例如上面的第二条插入会到视图中,第一条不会,第一条插入会到基本表中去

如果加了with check option的话就意味着这个视图的增改删操作必须要满足where 后面的条件才可以进行操作,不然就会报错,例如上面第一条插入4444的数据是软件工程专业,而where后面的条件是专业为计算机专业,所以会报错,插入失败,第二条同理会成功插入,也就是在这个例子中只能对专业是计算机专业的进行插入删除修改操作,如果专业不是计算机的就不能操作,但是可以对姓名增改删操作,因为where后面的条件并没有对姓名做出要求,只要你要操作的那个姓名他的专业是计算机就行
真题


5.7 索引


真题

6、数据库的控制功能
6.1 事务管理

真题

6.2 数据库备份和恢复



真题


把对数据的增删改操作写到日志文件中
6.3 并发控制

并发带来的问题


并发控制技术封锁

真题


7、分布式数据库


8、数据库设计
8.1 数据库设计步骤
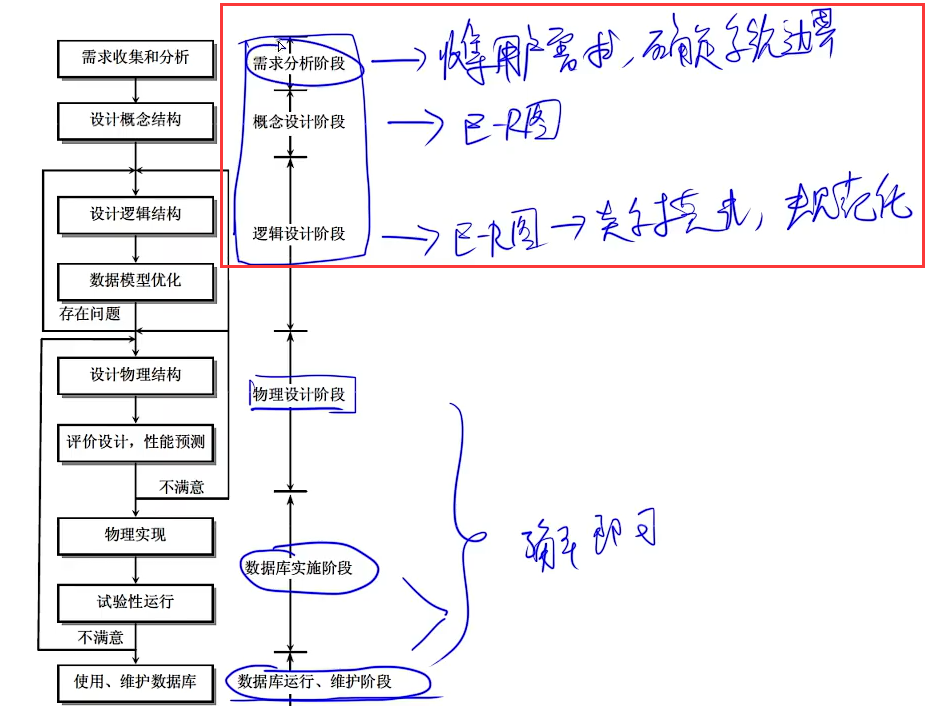

- 需求分析阶段的任务是:对现实世界要处理的对象(组织、部门、企业等)进行详细调查,在了解现行系统的概况,确定新系统功能的过程中,确定系统边界、收集支持系统目标的基础数据及其处理方法。
- 逻辑设计阶段的任务之一是对关系模式进一步的规范化处理。因为生成的初始关系模式并不能完全符合要求,会有数据冗余、更新异常存在,这就需要根据规范化理论对关系模式进行分解,以消除冗余和更新异常。不过有时根据处理要求,可能还需要增加部分冗余以满足处理要求。逻辑设计阶段的任务就需要作部分关系模式的处理,分解、合并或增加冗余属性,提高存储效率和处理效率。
8.2 需求分析




8.3 E-R图 (概念设计阶段)


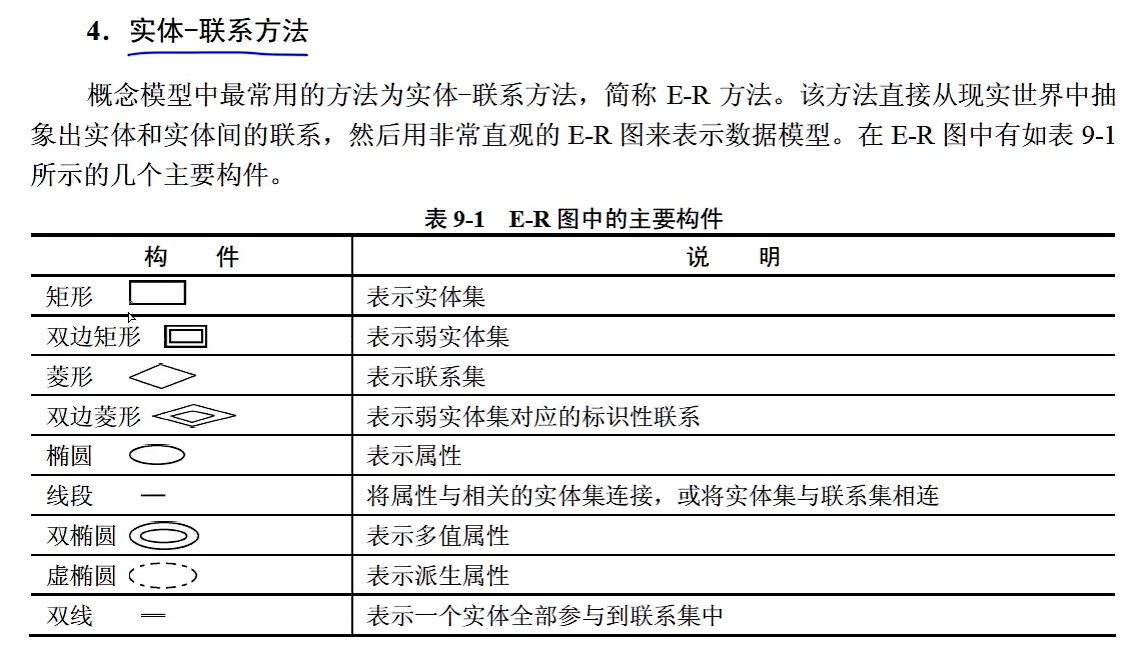
多值属性
**多值属性(multivalued attribute):**一个实体的某个属性可以有多个不同的取值,例如一本书的分类属性,这本书有多个分类,例如科学、医学等,这个分类就是多值属性, 用双线椭圆表示。
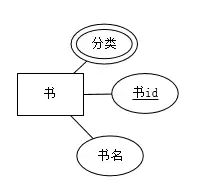
派生属性
**派生属性(derivers attribute):**是非永久性存于数据库的属性。派生属性的值可以从别的属性值或其他数据(如当前日期)派生出来,用虚线椭圆表示
弱实体
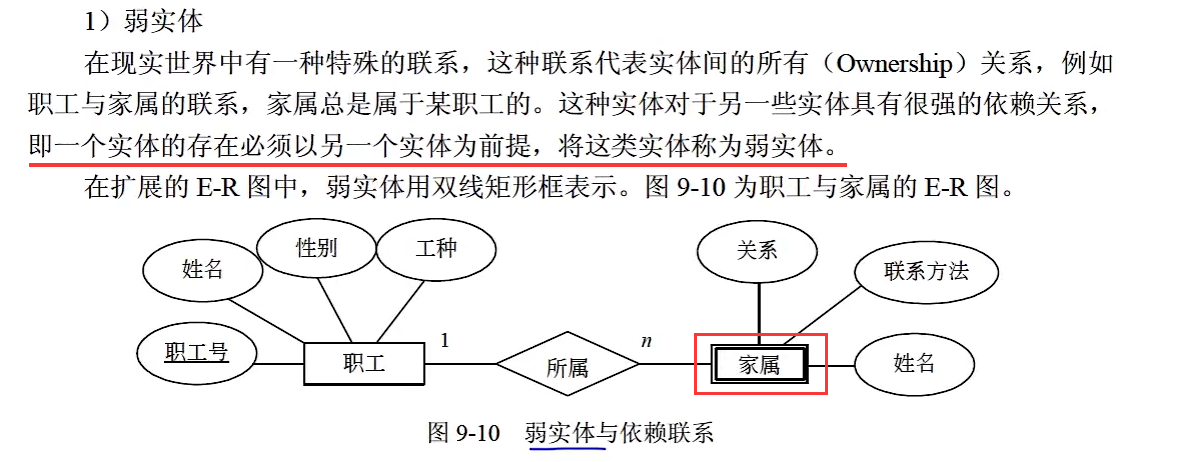
真题


讲解地址:https://www.bilibili.com/video/BV1LZ4y1k7ma?p=113
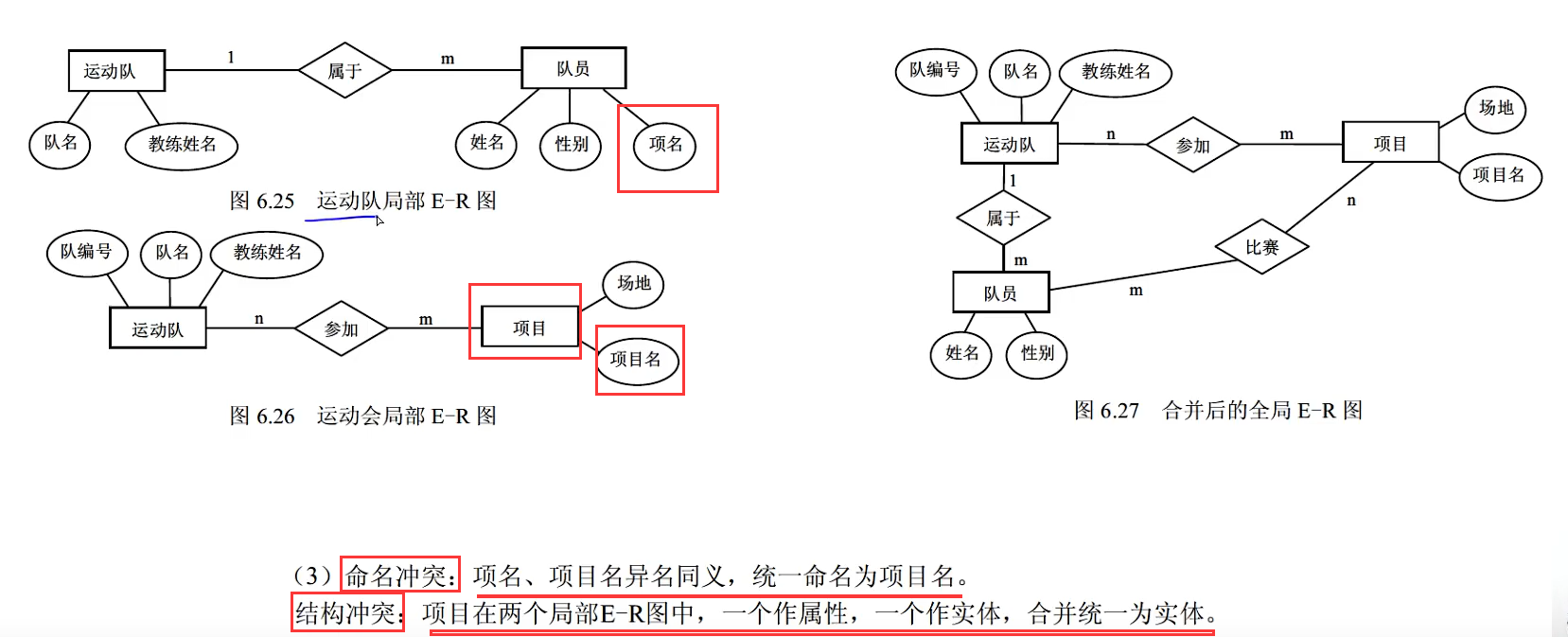
8.4 概念设计(合并E-R图)



重点是这个E-R图合并的时候的三种冲突

8.5 逻辑设计(把E-R图转为对应的关系模式)
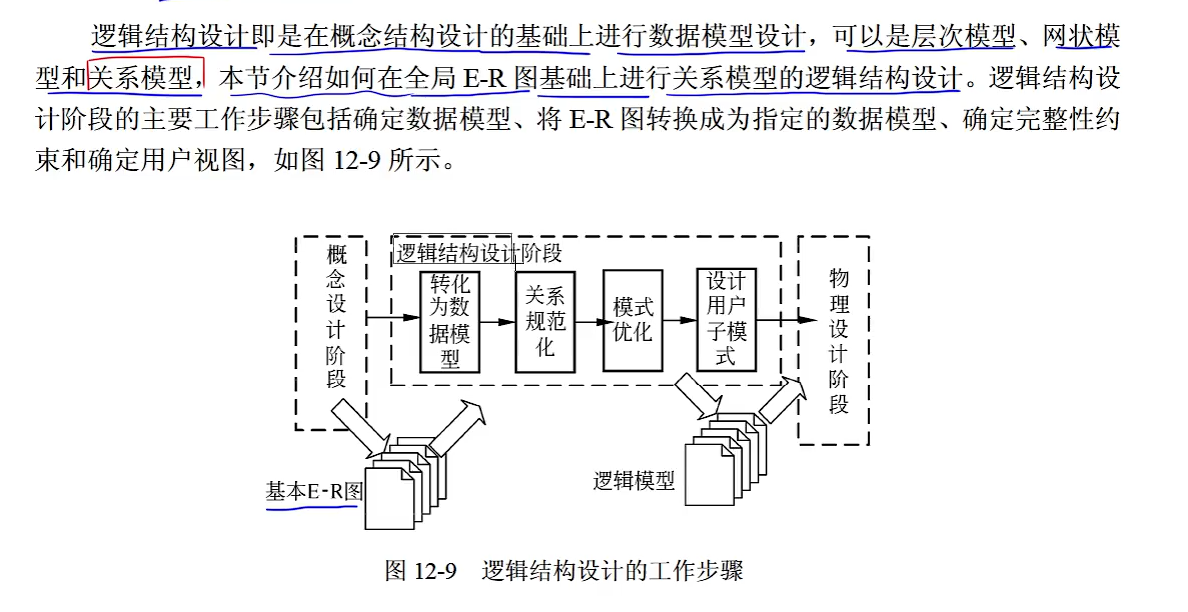
一对一转换
一对一转换就是把联系对应的属性随便放到一个实体里面(注意联系本身不放),然后把另外的实体的主键也放到该实体里
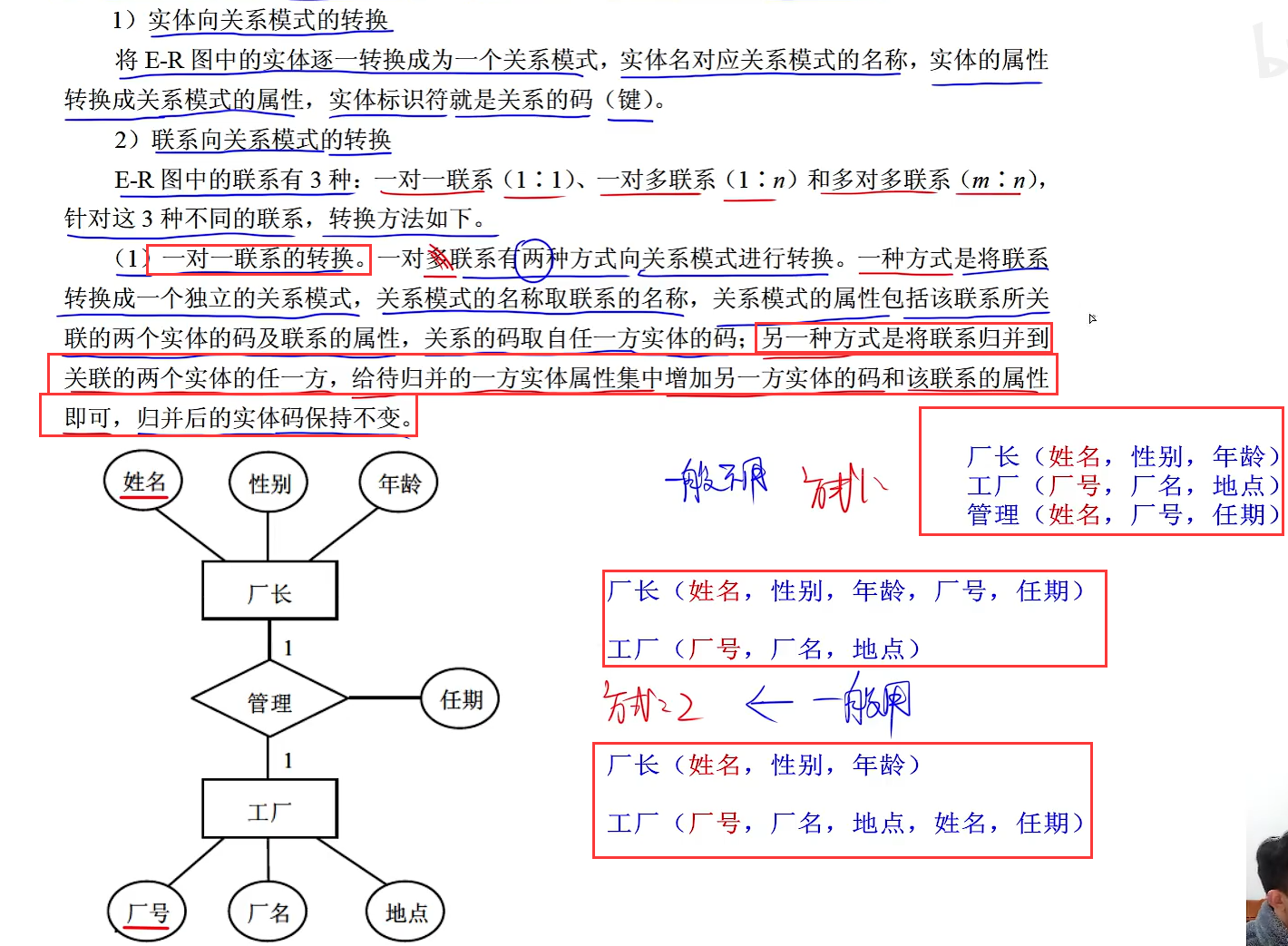
一对多转换
一对多转换就是把联系对应的属性放到多方实体类中(注意联系本身不放),并且把其他实体的主键也放到该多方实体类中
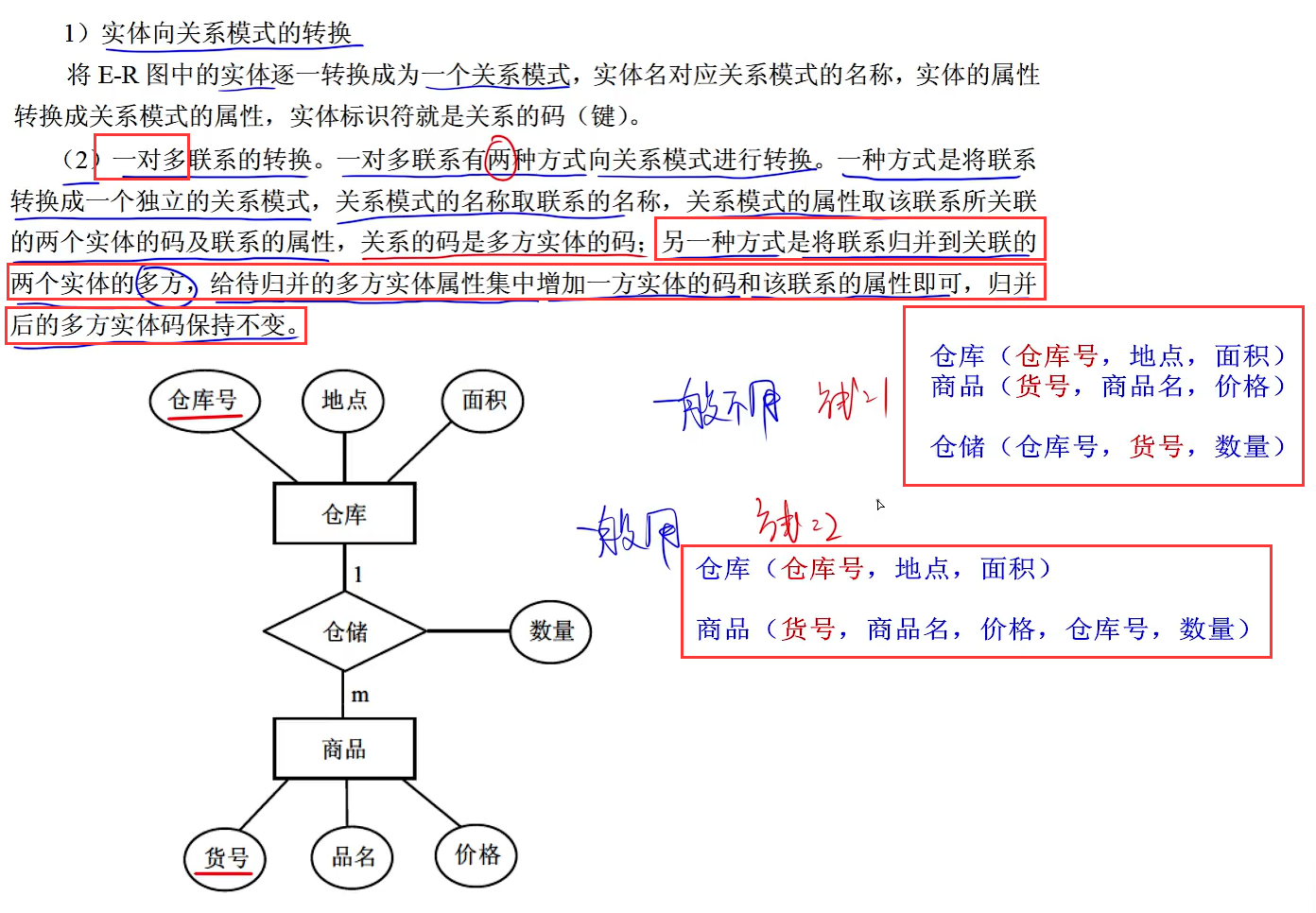
多对多转换
多对多转换就是把联系单独作为一个新的关系,把对应联系的实体的主键的组合作为这个新关系的主键
关系模式的规范化

8.6 真题
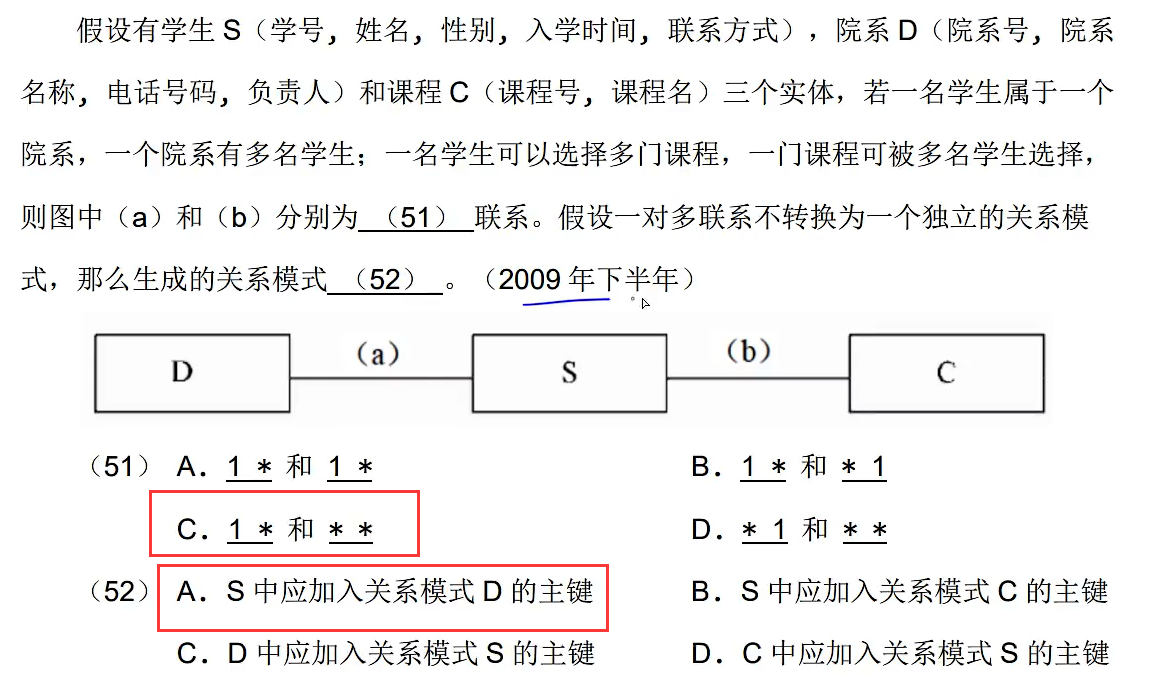



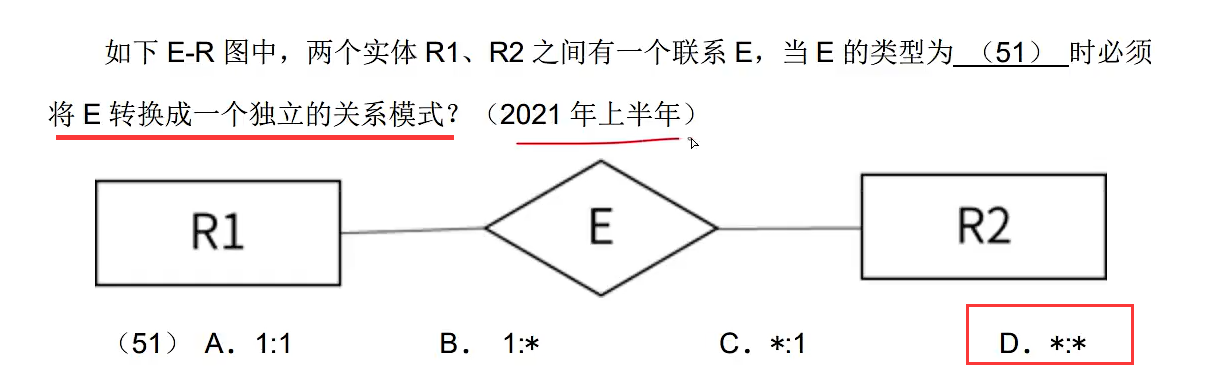



杂
杂题1
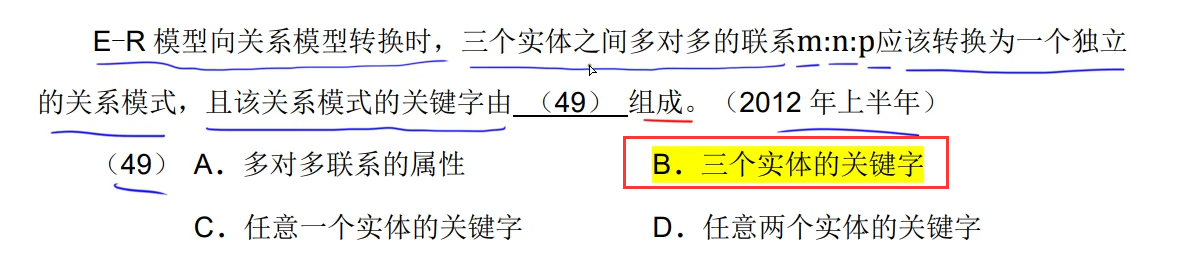
多对多的转换是要转换成一个新的关系模式,并且把对应的实体的主键作为候选键
杂题2

杂题3

杂题4

杂题5

杂题6

评论区